
20강 행 개수 구하기 - COUNT
- 집계함수
COUNT()
SUM()
AVG()
MIN()
MAX()

- COUNT 로 행 개수 구하기

인수로 집합을 지정한다.
COUNT의 인수는 * 이고 이는 '모든 열=테이블 전체' 라는 의미로 사용된다.
(* 를 인수로 사용할 수 있는 것은 COUNT 함수 뿐이다.)
집계함수는 집합에서 하나의 값을 계산해낸다
-> 집계

SELECT 가 WHERE 보다 나중에 지정되기 때문에, 검색된 행이 COUNT 로 넘겨진다.
WHERE 구 조건에 맞는 행의 개수를 구할 수 있다.
- 집계함수와 NULL 값

집계함수는 집합 안에 NULL 값이 있는 경우 이를 제외하고 처리한다.
no 열에는 NULL 값이 없어 5 가 나오지만, name 열에는 NULL 값이 1개 존재하므로 4 가 나온다.
- DISTINCT 로 중복 제거
집합 안에 중복된 값이 있는 경우 중복된 값을 제거하는 함수가 DISTINCT 이다.


default 는 ALL 이다.
- 집계함수에서 DISTINCT
NULL 값을 제외하고 중복하지 않는 데이터의 개수를 구할 수 있다.

21강 COUNT 이외의 집계함수
- SUM 으로 합계 구하기

SUM 집계함수에 지정되는 집합은 수치형 뿐이다.
-> 문자열형이나 날짜시간형의 집합에서 합계를 구할 수 없다. (SUM(name) 불가능)
NULL 값을 무시한다.
- AVG 로 평균 내기

AVG 집계함수도 NULL 값은 무시한다.
NULL을 0으로 간주해 평균을 내고 싶다면 CASE를 사용해 NULL을 0으로 변환한 뒤 계산하면 된다.

- MIN, MAX 로 최솟값, 최댓값 구하기
문자열형, 날짜시간형에도 사용이 가능하다.
NULL 값은 무시한다.

22강 그룹화 - GROUP BY
| no | name | quantity |
| 1 | A | 1 |
| 2 | A | 2 |
| 3 | B | 10 |
위와 같은 테이블이 존재할 때, GROUP BY 구를 사용해 GROUP BY name 을 하게 되면
A그룹, B그룹으로 묶이게 된다.
- GROUP BY 로 그룹화

DISTINCT 와 같이 중복을 제거하는 효과가 있다.
GROUP BY 는 집계함수와 함께 사용해야 한다.
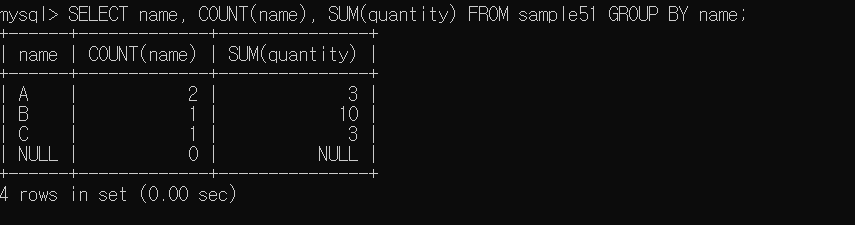
A 그룹 -> COUNT(name) -> 2
ex ) 점포별, 부서별, 분기별, ... 등 특정 단위로 집계할 때 사용한다.
- HAVING 구로 조건 지정

WHERE - GROUP BY - HAVING - SELECT - ORDER BY 로 처리되기 때문에 그룹화보다 WHERE 구로 행 검색하는 처리가 앞서게 되어 오류가 발생한다.
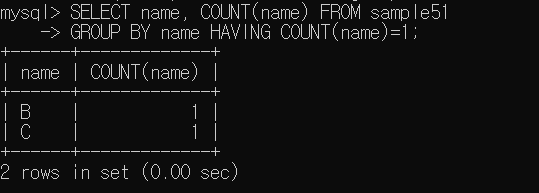
SELECT 구보다 먼저 처리되므로 별명 사용이 불가능하다. (Oracle)
- 복수열의 그룹화
SELECT no, name, quantity FROM sample51 GROUP BY name;
-> no, quantity 는 db 제품에 따라 사용할 수 없다.
-> GROUP BY 로 그룹화하여 그룹당 하나의 행을 반환하지만, quantity 는 1과 2로 두 개이기 때문에 반환할 하나의 값을 정하지 못했기 때문이다.
-> 집계함수를 사용하면 하나의 값으로 계산되므로 출력이 가능하다.
- 결괏값 정렬

23강 서브쿼리
- 서브쿼리는 SELECT 명령에 의한 데이터 질의로, 상부가 아닌 하부의 부수적인 질의이다.
- SELECT, FROM, WHERE 구 등 SELECT 명령의 각 구를 기술할 수 있다.
- WHERE 구는 SELECT, DELETE, UPDATE 구에서 사용할 수 있는데 이들 중 어떤 명령에서든 서브쿼리를 사용할 수 있다.
- DELETE 의 WHERE 구에서 서브쿼리 사용하기


- 스칼라 값
SELECT 명령이 어떤 값을 반환하는지 주의해야 한다.
- 하나의 값을 반환 -> 스칼라 값 (서브쿼리 사용이 쉽다.)
- 복수의 행이 반환되지만 열은 하나 반환
- 하나의 행이 반환되지만 열은 복수 반환
- 복수의 행, 복수의 열 반환
'= 연산자' 를 사용하여 비교할 경우에는 스칼라 값끼리 비교해야 한다.
스칼라 값을 반환하는 서브쿼리를 '스칼라 서브쿼리' 라고 부른다.
집계함수는 WHERE 구에 사용할 수 없지만 '스칼라 서브쿼리' 라면 사용할 수 있다. (집계함수를 사용해 집계한 결과를 조건식으로 사용할 수 있다.)
GROUP BY에서 지정한 그룹에 다른 값이 여러 개 존재할 경우는 스칼라 값이라고 할 수 없다.
- SELECT 구에서 서브쿼리 사용하기

MySQL 에선 SELECT 명령에 FROM 구가 없어도 되지만, Oracle 등 전통적 db 제품에선 생략이 불가능하다.
-> FROM DUAL 을 지정하면 실행이 가능하다.
- SET 구에서 서브쿼리 사용하기
- FROM 구에서 서브쿼리 사용하기
FROM 구에 기술할 경우에는 스칼라 값을 반환하지 않아도 된다.

SELECT 명령 안에 SELECT 명령이 들어있는 구조
-> 네스티드(nasted) 구조
- 실제 업무에서 FROM 구에 서브쿼리를 지정하여 사용하는 경우
SELECT * FROM (
SELECT * FROM sample54 ORDER BY a DESC
) sq
WHERE ROWNUM<=2;
Oracle 은 LIMIT 구가 없기 때문에 서브쿼리에서 정렬 후 상위 2개 행을 추출할 수 있다.
- INSERT 명령과 서브쿼리

SELECT 명령이 반환하는 값이 스칼라 값일 필요는 없으나 자료형이 일치해야 한다.
24강 서브쿼리
- EXISTS
결과값이 있는지를 조사할 수 있다.

- NOT EXISTS


- 상관 서브쿼리
부모 명령과 자식인 서브쿼리가 특정 관계를 맺는 것을 '상관 서브쿼리' 라고 부른다.
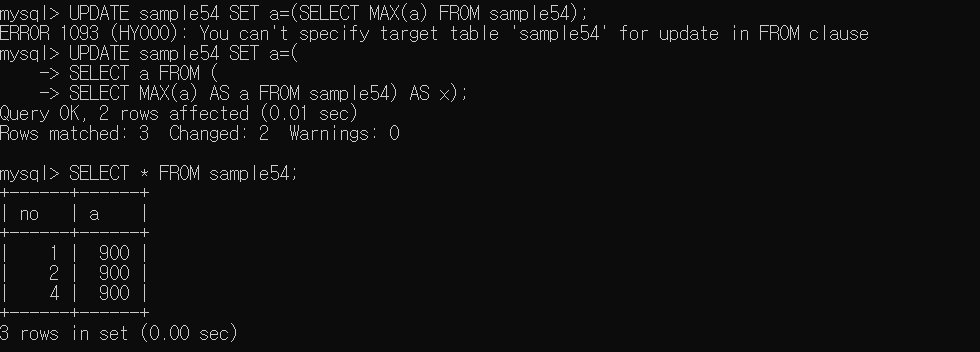
DELETE FROM sample54 WHERE a=(SELECT MIN(a) FROM sample54);
SELECT MIN(a) FROM sample54;
-> 단독 실행 가능(단독 쿼리)

부모 명령과 연관되어 처리되기 때문에 단독으로 실행시킬 수 없다.
- IN
스칼라 값끼리 비교할 ㄸ는 '= 연산자' 를 사용했지만 집합을 비교할 때는 IN 을 사용한다.
IN 을 사용하면 집합 안에 값이 존재하는지를 조사할 수 있다.
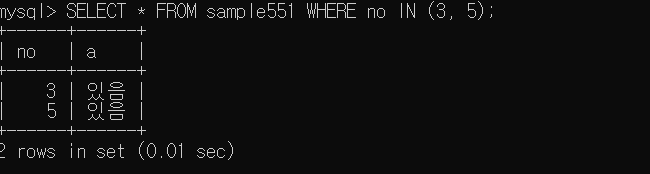

- IN과 NULL
IN 에서는 집합 안에 NULL 값이 있어도 무시하지 않는다.
IS NULL 을 사용해야 NULL 비교가 가능하다.
NOT IN 의 경우 집합 안에 NULL 값이 있으면 왼쪽 값이 집합 안에 포함되어 있지 않더라도 참을 반환하지 않고 불명(UNKNOWN) 을 반환한다.
'SQL' 카테고리의 다른 글
| [6장] 데이터베이스 객체 작성과 삭제 (0) | 2022.11.21 |
|---|---|
| [4장] 데이터의 추가, 삭제, 갱신 (0) | 2022.10.30 |
| [3장] 정렬과 연산 (1) | 2022.10.23 |
| [2장] 테이블에서 데이터 검색 (0) | 2022.10.02 |
| [1장] 데이터베이스와 SQL (0) | 2022.09.24 |