
복잡도
자료 구조(data structure)는 효율적으로 데이터를 관리하고 수정, 삭제, 탐색, 저장할 수 있는 데이터 집합이다.
복잡도는 시간 복잡도와 공간 복잡도로 나뉜다.
시간 복잡도
시간 복잡도란 '입력 크기에 대해 어떠한 알고리즘이 실행되는 데 걸리는 시간'이다. 주요 로직의 반복 횟수를 중점으로 측정되며, 보통 빅오 표기법으로 나타낸다.
빅오 표기법
예를 들어 '입력 크기 n'의 모든 입력에 대한 알고리즘에 필요한 시간이 10n^2+n 이라고 한다면 다음과 같은 코드를 작성할 수 있다.
for (int i = 0; i < 10; i++) {
for (int j = 0; j < n; j++) {
for (int k = 0; k < n; k++ {
//처리 로직
}
}
}
for (int i = 0; i < n; i++) {
//처리 로직
}
빅오 표기법이란 입력 범위 n을 기준으로 해서 로직이 몇 번 반복되는지 나타내는 것인데, 위 코드의 시간 복잡도를 빅오 표기법으로 나타내면 O(n^2)이 된다.
'가장 영향을 많이 끼치는' 항의 상수 인자를 빼고 나머지 항을 없앤 것이다. 다른 항들은 증가 속도를 고려하면 신경 쓰지 않아도 된다. 입력 크기가 커질수록 연산량이 가장 많이 커지는 항은 n의 제곱항이고, 다른 것은 그에 비해 미미하기 때문에 이것만 신경 쓰면 된다는 이론이다.
시간 복잡도의 존재 이유
시간 복잡도는 효율적인 코드로 개선하는 데 쓰이는 척도가 된다. O(n^2)의 시간 복잡도를 가지는 로직이 9초가 걸린다면, 이를 O(n)의 시간 복잡도를 가지는 알고리즘으로 개선 시 3초가 걸리게 된다.
시간 복잡도의 속도 비교

O(1)과 O(n)은 입력 크기가 커질수록 차이가 많이 된다. 즉, O(n^2)보다는 O(n), O(n)보다는 O(1)을 지향해야 한다.
공간 복잡도
공간 복잡도는 프로그램을 실행시켰을 때 필요로 하는 자원 공간의 양을 말한다. 정적 변수로 선언된 것 말고도 동적으로 재귀적인 함수로 인해 공간을 계속해서 필요로 할 경우도 포함한다.
int[] arr = new int[1004];
arr 배열은 1004 * 4byte 의 크기를 가지게 된다. 이런 공간을 의미한다.
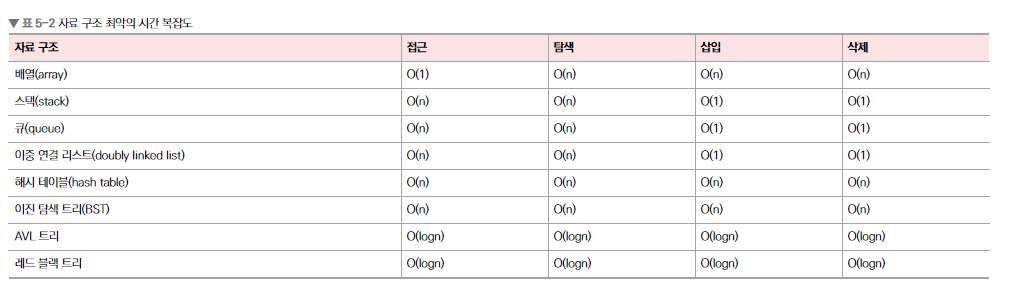
자료 구조에서의 시간 복잡도
자료 구조를 쓸 때는 시간 복잡도를 잘 생각해야 한다. 보통 시간 복잡도를 생각할 때는 평균, 최악의 시간 복잡도를 고려하며 쓴다.

선형 자료 구조
선형 자료 구조란 요소가 일렬로 나열되어 있는 자료 구조이다.
연결 리스트
연결 리스트는 데이터를 감싼 노드를 포인터로 연결해서 동적으로 메모리를 할당하거나 크기 조정이 필요할 때 유리한 자료 구조이다. 삽입과 삭제가 O(1) 걸리며 탐색에는 O(n)이 걸린다.

prev 포인터와 next 포인터로 앞과 뒤의 노드를 연결시킨 것이 연결 리스트이며, 연결 리스트에는 단순 연결 리스트, 원형 연결 리스트, 이중 연결 리스트가 있다. 맨 앞에 있는 노드를 헤드(head)라고 한다.
- 단순 연결 리스트 : next 포인터만 가진다.
- 원형 연결 리스트 : 마지막 노드의 next 포인터가 헤드 노드를 가리킨다.
- 이중 연결 리스트 : next 포인터와 prev 포인터를 가진다.
자바의 'java.util' 패키지의 LinkedList는 이중 연결 리스트로 구현되어 있다.
import java.util.LinkedList;
public class DoublyLinkedListExample {
public static void main(String[] args) {
// LinkedList 인스턴스 생성
LinkedList<Integer> list = new LinkedList<>();
// 요소 추가
list.add(1);
list.add(2);
list.add(3);
System.out.println("Initial list: " + list);
// 중간에 요소 추가
list.add(1, 5); // 인덱스 1 위치에 5 추가
System.out.println("After adding 5 at index 1: " + list);
// 요소 제거
list.remove(2); // 인덱스 2 위치의 요소 제거
System.out.println("After removing element at index 2: " + list);
// 요소 접근
int firstElement = list.getFirst();
int lastElement = list.getLast();
System.out.println("First element: " + firstElement);
System.out.println("Last element: " + lastElement);
// 요소 탐색
int index = list.indexOf(3);
System.out.println("Index of element 3: " + index);
// 리스트 출력
System.out.print("Final list: ");
for (int element : list) {
System.out.print(element + " ");
}
System.out.println();
}
}
class DoublyLinkedList { //직접 구현
//노드
class Node {
int data;
Node prev;
Node next;
Node(int data) {
this.data = data;
}
}
private Node head;
private Node tail;
// 노드를 끝에 추가하는 메소드
public void addLast(int data) {
Node newNode = new Node(data);
if (head == null) {
head = newNode;
tail = newNode;
} else {
tail.next = newNode;
newNode.prev = tail;
tail = newNode;
}
}
// 연결 리스트에서 노드를 삭제하는 메소드
public void remove(Node node) {
if (node == null || head == null) return;
if (node == head) {
head = node.next;
if (head != null) head.prev = null;
} else if (node == tail) {
tail = node.prev;
if (tail != null) tail.next = null;
} else {
node.prev.next = node.next;
node.next.prev = node.prev;
}
}
// 전체 노드 출력 메소드
public void display() {
Node current = head;
while (current != null) {
System.out.print(current.data + " ");
current = current.next;
}
System.out.println();
}
// 값으로 노드를 찾아 반환하는 메소드
public Node find(int data) {
Node current = head;
while (current != null) {
if (current.data == data) {
return current;
}
current = current.next;
}
return null;
}
public static void main(String[] args) {
DoublyLinkedList dll = new DoublyLinkedList();
dll.addLast(1);
dll.addLast(2);
dll.addLast(3);
dll.display(); // Output: 1 2 3
Node node = dll.find(2);
dll.remove(node);
dll.display(); // Output: 1 3
}
}
배열
배열(array)는 같은 타입의 변수들로 이루어져 있고, 크기가 정해져 있으며, 인접한 메모리 위치에 있는 데이터를 모아놓은 집합이다. 또한, 중복을 허용하고 순서가 있다.
여기서 설명하는 배열은 '정적 배열' 기반이다. 접근(참조)에는 O(1)의 시간 복잡도를 가지며 랜덤 접근(random access)이 가능하다. 삽입과 삭제에는 O(n)이 걸린다. 따라서 데이터 추가와 삭제가 많을 경우 연결 리스트, 접근(참조)을 많을 경우 배열로 하는 것이 좋다.
랜덤 접근과 순차적 접근
직접 접근이라고 하는 랜덤 접근은 동일한 시간에 배열과 같은 순차적인 데이터가 있을 때 임의의 인덱스에 해당하는 데이터에 접근할 수 있는 기능이다. 데이터를 저장된 순서대로 검색해야 하는 순차적 접근과는 반대이다.
배열과 연결 리스트 비교
배열은 상자를 순서대로 나열한 데이터 구조로 몇 번째 상자인지만 알면 해당 상자의 요소를 끄집어낼 수 있다.
연결 리스트는 상자를 선으로 연결한 형태의 데이터 구조로 상자의 요소를 알기 위해서는 하나씩 상자 내부를 확인해봐야 한다.
n번째 요소의 접근(참조)은 배열이 빠르고 연결 리스트는 느리다. 배열의 경우 n번째 상자 요소에 접근하면 되기 때문에 O(1)의 시간 복잡도를 가지고, 연결 리스트는 매번 상자를 주어진 선을 기반으로 순차적으로 열어야 하기 때문에 접근(참조)의 경우 O(n)의 시간 복잡도를 가진다. 즉, 참조가 많이 일어나는 작업의 경우 배열이 빠르고 연결 리스트는 느리다.
하지만 데이터 추가 및 삭제는 연결 리스트가 더 빠르고 배열은 느리다. 배열은 모든 상자를 앞으로 옮겨야 추가가 가능하지만, 연결 리스트는 선을 바꿔서 연결해주기만 하면 된다.
벡터
벡터(vector)는 동적으로 요소를 할당할 수 있는 동적 배열이다. 컴파일 시점에 개수를 모른다면 벡터를 써야 한다. 또한, 중복을 허용하고 순서가 있고 랜덤 접근이 가능하다. 탐색과 맨 뒤의 요소를 삭제하거나 삽입하는 데 O(1)이 걸리며, 맨 뒤가 아닌 요소를 삭제하고 삽입하는 데 O(n)의 시간이 걸린다.
자바의 'Vector' 클래스는 기본적으로 용량이 초과할 때마다 두 배로 증가하도록 설계되어 있다. 하지만, 초기 용량과 용량 증가 값을 설정하여 이 동작을 사용자 정의할 수 있다.
import java.util.Vector;
public class VectorDefaultCapacityExample {
public static void main(String[] args) {
// 기본 용량 증가 메커니즘을 사용하는 벡터 생성
Vector<Integer> vector = new Vector<>();
System.out.println("Initial capacity: " + vector.capacity());
// 요소 추가
for (int i = 1; i <= 10; i++) {
vector.add(i);
System.out.println("Added element: " + i + ", Current capacity: " + vector.capacity());
}
}
}import java.util.Vector;
public class VectorCapacityExample {
public static void main(String[] args) {
// 초기 용량이 5이고 용량 증가 값이 2인 벡터 생성
Vector<Integer> vector = new Vector<>(5, 2);
System.out.println("Initial capacity: " + vector.capacity());
// 요소 추가
for (int i = 1; i <= 10; i++) {
vector.add(i);
System.out.println("Added element: " + i + ", Current capacity: " + vector.capacity());
}
}
}
Vector가 현재 용량을 초과하지 않는 경우 맨 뒤에 요소를 삽입하는 작업은 단순히 배열의 마지막 인덱스에 값을 추가하는 것이므로 O(1) 시간이 걸린다.
만약 용량을 초과하는 경우 Vector는 배열의 크기를 두 배로 증가시키고, 기존 배열의 모든 요소를 새로운 배열로 복사한다. 이 작업은 O(n)의 시간이 걸린다. 하지만 이런 크기 증가와 복사는 요소가 삽입될 때마다 발생하지 않는다.
따라서, 많은 요소를 삽입할 경우 전체 삽입 작업의 평균 시간은 O(1)이 된다. 이는 Vector가 크기를 두 배 증가시키는 방식의 이점이다.
import java.util.Vector;
public class VectorExample {
public static void main(String[] args) {
// Vector 인스턴스 생성
Vector<Integer> vector = new Vector<>();
// 요소 추가
vector.add(1);
vector.add(2);
vector.add(3);
System.out.println("Initial vector: " + vector);
// 중간에 요소 추가
vector.add(1, 5); // 인덱스 1 위치에 5 추가
System.out.println("After adding 5 at index 1: " + vector);
// 요소 제거
vector.remove(2); // 인덱스 2 위치의 요소 제거
System.out.println("After removing element at index 2: " + vector);
// 요소 접근
int firstElement = vector.firstElement();
int lastElement = vector.lastElement();
System.out.println("First element: " + firstElement);
System.out.println("Last element: " + lastElement);
// 요소 탐색
int index = vector.indexOf(3);
System.out.println("Index of element 3: " + index);
// 벡터 크기 및 용량
int size = vector.size();
int capacity = vector.capacity();
System.out.println("Size: " + size);
System.out.println("Capacity: " + capacity);
// 벡터 출력
System.out.print("Final vector: ");
for (int element : vector) {
System.out.print(element + " ");
}
System.out.println();
}
}
스택
스택(stack)은 가장 마지막으로 들어간 데이터가 가장 첫 번째로 나오는 성질(LIFO, Last In First Out)을 가진 자료 구조이다. 재귀적인 함수, 알고리즘에 사용되며 웹 브라우저 방문 기록 등에 쓰인다. 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다.

import java.util.Stack;
public class StackExample {
public static void main(String[] args) {
// Stack 인스턴스 생성
Stack<Integer> stack = new Stack<>();
// 스택에 요소 추가 (push)
stack.push(1);
stack.push(2);
stack.push(3);
System.out.println("Stack after pushes: " + stack);
// 스택의 맨 위 요소 확인 (peek)
int topElement = stack.peek();
System.out.println("Top element: " + topElement);
// 스택에서 요소 제거 (pop)
int removedElement = stack.pop();
System.out.println("Removed element: " + removedElement);
System.out.println("Stack after pop: " + stack);
// 스택이 비어있는지 확인 (empty)
boolean isEmpty = stack.isEmpty();
System.out.println("Is stack empty? " + isEmpty);
// 스택의 크기 확인 (size)
int size = stack.size();
System.out.println("Stack size: " + size);
// 스택 전체 출력
System.out.print("Final stack: ");
for (int element : stack) {
System.out.print(element + " ");
}
System.out.println();
}
}
큐
큐(queue)는 먼저 집어넣은 데이터가 먼저 나오는 성질(FIFO, First In First Out)을 지닌 자료 구조이며, 스택과는 반대 개념을 가졌다. 삽입 및 삭제에 O(1), 탐색에 O(n)이 걸린다.
CPU 작업을 기다리는 프로세스, 스레드 행렬 또는 네트워크 접속을 기다리는 행렬, 너비 우선 탐색, 캐시 등에 사용된다.

import java.util.LinkedList;
import java.util.Queue;
public class QueueExample {
public static void main(String[] args) {
// Queue 인스턴스 생성 (LinkedList 사용)
Queue<Integer> queue = new LinkedList<>();
// 큐에 요소 추가 (offer)
queue.offer(1);
queue.offer(2);
queue.offer(3);
System.out.println("Queue after offers: " + queue);
// 큐의 맨 앞 요소 확인 (peek)
int frontElement = queue.peek();
System.out.println("Front element: " + frontElement);
// 큐에서 요소 제거 (poll)
int removedElement = queue.poll();
System.out.println("Removed element: " + removedElement);
System.out.println("Queue after poll: " + queue);
// 큐가 비어있는지 확인 (isEmpty)
boolean isEmpty = queue.isEmpty();
System.out.println("Is queue empty? " + isEmpty);
// 큐의 크기 확인 (size)
int size = queue.size();
System.out.println("Queue size: " + size);
// 큐 전체 출력
System.out.print("Final queue: ");
for (int element : queue) {
System.out.print(element + " ");
}
System.out.println();
}
}
비선형 자료 구조
비선형 자료 구조란 일렬로 나열하지 않고 자료 순서나 관계가 복잡한 구조를 말한다. 일반적으로 트리나 그래프를 말한다.
그래프
그래프는 정점과 간선으로 이루어진 자료 구조이다.
정점과 간선
어떠한 곳에서 어떠한 곳으로 무언가를 통해 간다고 했을 때 '어떠한 곳'은 정점(vertex)이고 '무언가'는 간선(edge)이 된다. 정점에서 나가는 간선을 해당 정점의 outdegree라고 하며, 들어오는 간선을 해당 정점의 indegree라고 한다. 만약 indegree나 outdegree 중 하나만 존재할 경우 단방향 간선이라고 하며, 둘 다 존재할 경우 양방향 간선이라고 한다.
정점 V, U가 있을 때 V로부터 나가는 간선이 3개, 들어오는 간선이 2개라면 outdegree는 3개, indegree는 2개가 된다. 정점은 약자로 V 또는 U라고 하며, 보통 어떤 정점으로부터 시작해서 어떤 정점까지 간다를 "U에서부터 V로 간다." 라고 표현한다. 정점과 간선으로 이루어진 집합을 '그래프(graph)'라고 한다.
가중치
가중치는 정점과 정점 사이에 드는 비용이다. 1번 노드와 2번 노드까지 가는 비용이 한 칸이라면 1번 노드에서 2번 노드까지의 가중치는 한 칸이다.
트리
트리는 그래프 중 하나로 그래프의 특징처럼 정점과 간선으로 이루어져 있고, 트리 구조로 배열된 일종의 계층적 데이터 집합이다. 루트 노드, 내부 노드, 리프 노드 등으로 구성된다. 트리로 이루어진 집합을 숲이라고 한다.

1. 부모, 자식 계층 구조를 가진다. B 노드는 D와 E 노드의 부모 노드이고, D와 E 노드는 B 노드의 자식 노드이다. 같은 경로상에서 어떤 노드보다 위에 있으면 부모, 아래에 있으면 자식 노드가 된다.
2. V - 1 = E 라는 특징이 있다. 간선 수는 노드 수 - 1 이다.
3. 임의의 두 노드 사이의 경로는 '유일무이' 하게 '존재'한다. 즉, 트리 내의 어떤 노드와 어떤 노드까지의 경로는 반드시 있다.
트리의 구성
트리는 루트 노드, 내부 노드, 리프 노드로 이루어져 있다.
루트 노드
가장 위에 있는 노드이다. 보통 트리 문제가 나오고 트리를 탐색할 때 루트 노드를 중심으로 탐색하면 문제가 쉽게 풀리는 경우가 많다.
내부 노드
루트 노드와 리프 노드 사이에 있는 노드를 뜻한다.
리프 노드
리프 노드는 자식 노드가 없는 노드를 뜻한다.
트리의 높이와 레벨

- 깊이 : 트리에서의 깊이는 각 노드마다 다르며, 루트 노드부터 특정 노드까지의 최단 거리로 갔을 때의 거리를 말한다. 예를 들어 G 노드의 깊이는 2이다.
- 높이 : 트리의 높이는 루트 노드부터 리프 노드까지의 거리 중 가장 긴 거리를 의미하며, 위 그림의 높이는 3이다.
- 레벨 : 레벨은 보통 깊이와 같은 의미를 지닌다. A 노드를 0레벨이라 하고 B, C, D, E 노드까지의 레벨을 1레벨이라고 할 수 있고, A 노드를 1레벨이라고 한다면 B, C, D, E 노드는 2레벨이 된다.
- 서브트리 : 트리 내의 하위 집합을 서브트리라고 한다. 트리 내의 부분집합이라고도 보면 된다. 서브 트리는 해당 노드와 그 모든 하위 노드로 구성된다. 예를 들어 B의 서브 트리는 {B, F, G} 이다.
이진 트리
이진 트리는 자식의 노드 수가 두 개 이하인 트리이다.

- 정이진 트리(full binary tree) : 자식 노드가 0 또는 2인 이진 트리
- 완전 이진 트리(complete binary tree) : 왼쪽에서부터 채워져 있는 이진 트리, 마지막 레벨을 제외하고는 모든 레벨이 완전히 채워져 있으며, 마지막 레벨의 경우 왼쪽부터 채워져 있다.
- 변질 이진 트리(degenerate binary tree) : 자식 노드가 하나밖에 없는 이진 트리
- 포화 이진 트리(perfect binary tree) : 모든 노드과 꽉 차 있는 이진 트리
- 균형 이진 트리(balanced binary tree) : 왼쪽과 오른쪽 노드의 높이 차이가 1 이하인 이진 트리이다. map, set을 구성하는 레드 블랙 트리는 균형 이진 트리 중 하나이다.
이진 탐색 트리
이진 탐색 트리(BST)는 노드의 오른쪽 하위 트리에는 '노드 값보다 큰 값'이 있는 노드만 포함되고, 왼쪽 하위 트리에는 '노드 값보다 작은 값'이 들어 있는 트리이다.

이 때 왼쪽 및 오른쪽 하위 트리도 해당 특성을 가진다. 이렇게 두면 '검색'을 하기에 용이하다. 왼쪽에는 작은 값, 오른쪽에는 큰 값이 이미 정해져 있기 때문에 5를 찾으려고 한다면 22의 왼쪽 노드들만 찾으면 된다. 보통 요소를 찾을 때 이진 탐색 트리의 경우 O(logn)이 걸린다. 하지만 최악의 경우 O(n)이 걸린다.
그 이유는 이진 탐색 트리는 삽입 순서에 따라 선형적일 수 있기 때문이다.
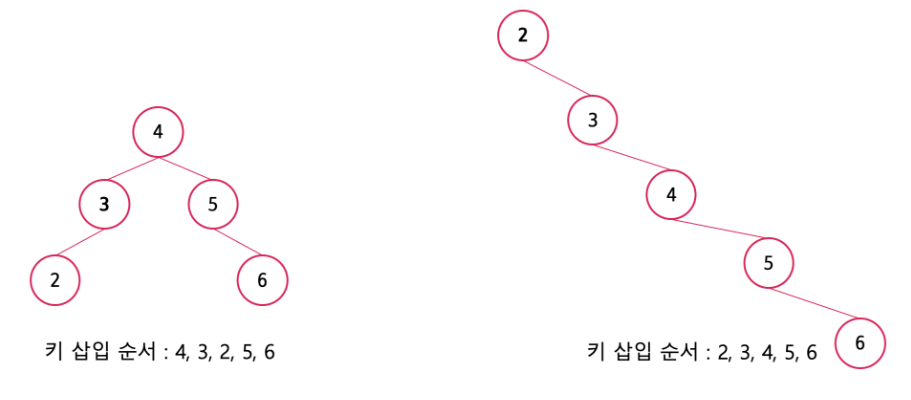
AVL 트리
AVL 트리(Adelson-Velsky and Landis tree)는 최악의 경우 선형적인 트리가 되는 것을 방지하고 스스로 균형을 잡는 이진 탐색 트리이다. 두 자식 서브트리의 높이는 항상 최대 1만큼 차이 난다는 특징이 있다.

이진 탐색 트리는 선형적인 트리 형태를 가질 때 최악의 경우 O(n)의 시간 복잡도를 가진다. 이러한 최악의 경우를 배제하고 항상 균형 잡힌 트리로 만들자. 라는 개념을 가진 트리가 바로 AVL 트리이다. 탐색, 삽입, 삭제 모두 시간 복잡도가 O(logn)이며 삽입, 삭제를 할 때마다 균형이 안 맞는 것을 맞추기 위해 트리 일부를 왼쪽 혹은 오른쪽으로 회전시키며 균형을 잡는다.
레드 블랙 트리

레드 블랙 트리는 균형 이진 탐색 트리로 탐색, 삽입, 삭제 모두 시간 복잡도가 O(logn)이다. 각 노드는 빨간색 또는 검은색의 색상을 나타내는 추가 비트를 저장하며, 삽입 및 삭제 중에 트리가 균형을 유지하도록 하는 데 사용된다. Java의 TreeMap과 TreeSet이 이 레드 블랙 트리를 이용하여 구현되어 있다.
TreeMap 클래스는 키-값 쌍을 저장하는 맵 인터페이스 구현체로, 키는 정렬된 순서로 저장된다.
TreeSet 클래스는 요소를 정렬된 순서로 저장하는 셋 인터페이스 구현체로, 중복 요소를 허용하지 않는다.
"모든 리프 노드와 루트 노드는 블랙이고 어떤 노드가 레드이면 그 노드의 자식은 반드시 블랙이다." 등의 규칙을 기반으로 균형을 잡는 트리이다.
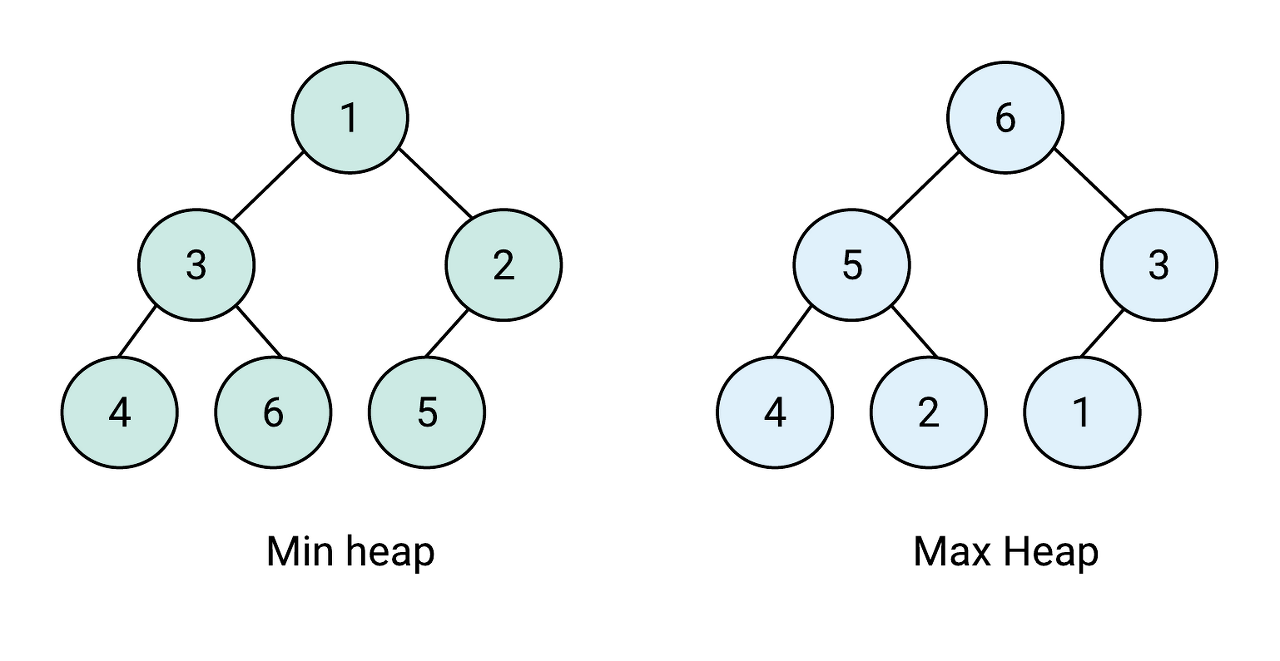
힙
완전 이진 트리 기반의 자료 구조로, 최소힙과 최대힙 두 가지가 있고 해당 힙에 따라 특정한 특징을 지킨 트리이다.
- 최대힙 : 루트 노드에 있는 키는 모든 자식에 있는 키 중에서 가장 커야 한다. 또한, 각 노드의 자식 노드와의 관계도 이와 같은 특징이 재귀적으로 이루어져야 한다.
- 최소힙 : 루트 노드에 있는 키는 모든 자식에 있는 키 중에서 최솟값이어야 한다. 또한, 각 노드의 자식 노드와의 관계도 이와 같은 특징이 재귀적으로 이루어져야 한다.
최대힙의 삽입
힙에 새로운 요소가 들어오면, 일단 새로운 노드를 힙의 마지막 노드에 이어 삽입한다. 이 새로운 노드를 부모 노드들과의 크기를 비교하며 교환해서 힙의 성질을 만족시킨다.
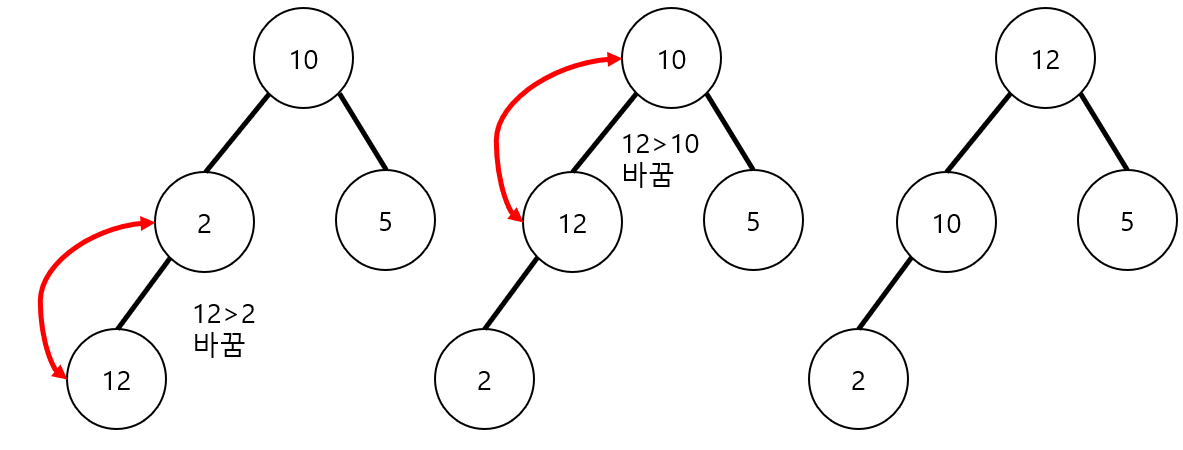
예를 들어 2라는 값을 가진 노드 밑에 12라는 값을 가진 노드를 삽입한다고 하면, 이 노드가 점차 올라가면서 해당 노드 위에 있는 노드와 스왑하는 과정을 거쳐 최대힙 조건을 만족한다.
최대힙의 삭제
최대힙에서 최댓값은 루트 노드이므로 루트 노드가 삭제되고, 그 이후 마지막 노드와 루트 노드를 스왑하여 또다시 스왑 등의 과정을 거쳐 재구성된다.
우선순위 큐
우선순위 큐는 우선순위 대기열이라고도 하며, 대기열에서 우선순위가 높은 요소가 우선순위가 낮은 요소보다 먼저 제공되는 자료 구조이다.

우선순위 큐는 힙을 기반으로 구현된다.
import java.util.PriorityQueue;
public class PriorityQueueExample {
public static void main(String[] args) {
// PriorityQueue 인스턴스 생성 (기본 자연 순서)
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();
// 요소 추가 (offer)
priorityQueue.offer(5);
priorityQueue.offer(1);
priorityQueue.offer(3);
priorityQueue.offer(7);
priorityQueue.offer(2);
// PriorityQueue 출력
System.out.println("PriorityQueue: " + priorityQueue);
// 우선순위가 가장 높은 요소 확인 (peek)
int topElement = priorityQueue.peek();
System.out.println("Top element (peek): " + topElement);
// 우선순위가 가장 높은 요소 제거 (poll)
int removedElement = priorityQueue.poll();
System.out.println("Removed element (poll): " + removedElement);
System.out.println("PriorityQueue after poll: " + priorityQueue);
// 큐의 크기 확인 (size)
int size = priorityQueue.size();
System.out.println("PriorityQueue size: " + size);
// 큐가 비어있는지 확인 (isEmpty)
boolean isEmpty = priorityQueue.isEmpty();
System.out.println("Is PriorityQueue empty? " + isEmpty);
// PriorityQueue 전체 출력
System.out.print("Final PriorityQueue: ");
while (!priorityQueue.isEmpty()) {
System.out.print(priorityQueue.poll() + " ");
}
System.out.println();
}
}
import java.util.PriorityQueue;
import java.util.Comparator;
public class CustomPriorityQueueExample {
public static void main(String[] args) {
PriorityQueue<String> customHeap = new PriorityQueue<>(Comparator.comparingInt(String::length));
customHeap.offer("apple");
customHeap.offer("banana");
customHeap.offer("cherry");
customHeap.offer("date");
customHeap.offer("fig");
while (!customHeap.isEmpty()) {
System.out.print(customHeap.poll() + " "); // 문자열 길이에 따라 출력
}
}
}
apple, banana, cherry ... 가 입력되었음에도 우선순위가 높은 banana가 출력된다.
맵
맵(map)은 특정 순서에 따라 키와 매핑된 값의 조합으로 형성된 자료 구조이다. 레드 블랙 트리 자료 구조를 기반으로 형성된다. 정렬을 보장하는 map과 정렬을 보장하지 않는 unordered_map이 있다. 자바 기준, TreeMap은 삽입하면 자동으로 정렬되지만 다른 Map은 정렬되지 않는다. HashMap은 순서가 없는 unordered_map과 유사하다. LinkedHashMap은 삽입 순서를 유지하는 자바 특유 자료 구조이다.
맵을 쓸 때는 Map<String, Integer> 형태로 구현한다. clear() 함수로 맵에 있는 모든 요소를 삭제할 수 있으며, size()로 map 크기를 구할 수 있다. 또한 remove()로 해당 키와 키에 매핑된 값을 지울 수 있다.
import java.util.HashMap;
import java.util.Map;
public class HashMapExample {
public static void main(String[] args) {
// HashMap 인스턴스 생성
Map<String, Integer> map = new HashMap<>();
// 요소 추가 (put)
map.put("apple", 1);
map.put("banana", 2);
map.put("cherry", 3);
map.put("date", 4);
// Map 출력
System.out.println("Initial Map: " + map);
// 특정 키에 대한 값 접근 (get)
int value = map.get("banana");
System.out.println("Value for key 'banana': " + value);
// 특정 키-값 쌍 제거 (remove)
map.remove("cherry");
System.out.println("Map after removing key 'cherry': " + map);
// Map의 모든 키-값 쌍 반복 (entrySet)
System.out.println("All key-value pairs:");
for (Map.Entry<String, Integer> entry : map.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// Map의 크기 확인 (size)
int size = map.size();
System.out.println("Map size: " + size);
// 특정 키가 존재하는지 확인 (containsKey)
boolean hasApple = map.containsKey("apple");
System.out.println("Does the map contain 'apple'? " + hasApple);
// 특정 값이 존재하는지 확인 (containsValue)
boolean hasValue4 = map.containsValue(4);
System.out.println("Does the map contain value 4? " + hasValue4);
}
}
셋
셋(set)은 고유한 요소를 저장하는 컨테이너이며, 중복되는 요소는 없고 오로지 희소한(unique) 값만 저장하는 자료 구조이다.
import java.util.HashSet;
import java.util.Set;
public class HashSetExample {
public static void main(String[] args) {
// HashSet 인스턴스 생성
Set<String> set = new HashSet<>();
// 요소 추가 (add)
set.add("apple");
set.add("banana");
set.add("cherry");
set.add("date");
// HashSet 출력
System.out.println("HashSet: " + set);
// 요소 제거 (remove)
set.remove("banana");
System.out.println("HashSet after removing 'banana': " + set);
// 특정 요소가 포함되어 있는지 확인 (contains)
boolean hasApple = set.contains("apple");
System.out.println("Does the set contain 'apple'? " + hasApple);
// Set의 크기 확인 (size)
int size = set.size();
System.out.println("Set size: " + size);
// Set의 모든 요소 반복 (for-each)
System.out.println("All elements in the set:");
for (String element : set) {
System.out.println(element);
}
}
}
해시 테이블
해시 테이블은 무한에 가까운 데이터들을 유한한 개수의 해시 값으로 매핑한 테이블이다. 삽입, 삭제, 탐색 시 평균적으로 O(1)의 시간 복잡도를 가지며 unordered_map으로 구현한다.