
NoSQL
NoSQL이란?

Not Only SQL의 약자로 기존 RDBM 형태의 관계형 데이터베이스가 아닌 비관계형 데이터베이스를 지칭한다.
기존의 정형화된 데이터 뿐만 아니라 메신저 텍스트, 음성 등 반정형화/비정형화된 데이터도 저장하고 다뤄야하는 수요가 생겼다.
이렇듯 데이터를 다룰 RDBMS로만 트래픽을 감당하기 어려워졌고, 이를 해결하기 위해 NoSQL이 등장했다. NoSQL은 대량의 분산된 데이터를 저장하고 조회하는 데 특화되었으며 스키마 없이 사용 가능하거나 느슨한 스키마를 제공한다.
또한 대량의 데이터를 빠르게 처리하기 위해 메모리에 임시 저장하고 응답하는 등의 방법을 사용한다.
동적인 스케일 아웃을 지원하기도 하며, 가용성을 위해 데이터 복제 등의 방법을 제공한다.
NoSQL의 핵심은 수평확장(Horizontal Scalability)와 고가용성(High Availability)이다.
RDBMS가 클라이언트-서버 환경에 맞는 데이터 저장기술이라면, NoSQL은 클라우드 환경에 맞는 저장 기술이다.
데이터량과 데이터 처리량이 계속 증가한다면,
1. 스키마 유연성 문제: 빅데이터를 RDBS에 미리 정의된 스키마에 맞춰 변경하려면 관리가 복잡해질 수 있다.
2. 스케일 아웃(Scale-out)의 제약: RDBMS는 애초에 단일 서버에서의 효율적인 작동을 염두에 두고 설계되어 있어 스케일 아웃(Scale out)이 제약될 수 있다. RDBMS에서는 이러한 확장이 관계형 데이터의 일관성과 트랜잭션 관리 복잡성으로 인해 비교적 어려울 수 있다.
NoSQL 특징
- 대용량 데이터 저장을 한다.
- 설계 단계부터 분산 처리를 염두에 두고 개발되었다. 반면, 전통적인 RDBMS는 단일 서버 환경에 최적화되어 설계되었다. RDBMS도 최근에는 분산처리 기능을 도입하고 있지만, 여전히 엄격한 데이터 무결성과 복잡한 트랜잭션 관리를 유지한다.
- 데이터 간의 관계를 정의하지 않기 때문에 테이블 간의 join 연산이 불가능하다.(Foreign Key와 같은 개념도 존재하지 않는다.)
- 읽기 작업보다 쓰기 작업이 더 빠르며, 일반적으로 RDBMS에 비하여 읽기와 쓰기 성능이 빠르다.
- (참고)단순한 단일 테이블 조회라면 RDBMS도 성능 차이가 크진 않다. 하지만 NoSQL은 대부분 메모리 사용율이 높다 보니 RDBMS보다는 읽기 속도가 빠른 편이다.
CAP
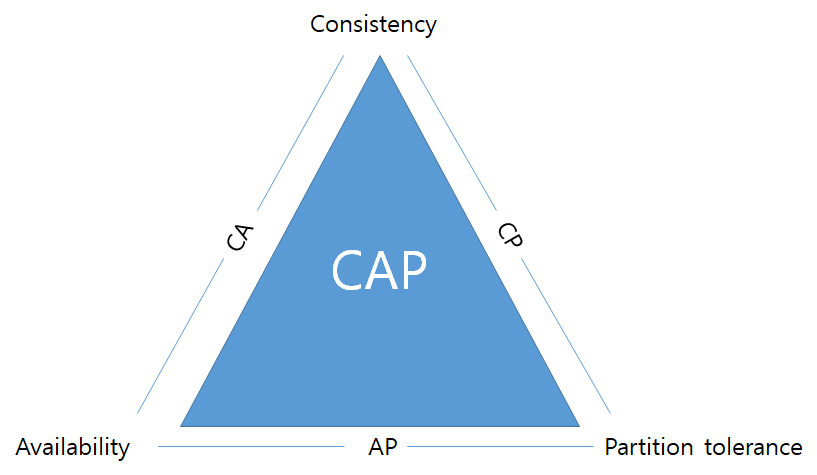
RDBMS는 ACID(원자성, 일관성, 고립성, 영구성)을 따른다. ACID는 DB의 트랜잭션이 안전하게 수행되는 것을 보장하기 위한 특성이다.
분산형 구조는 일관성(Consistency), 가용성(Availability), 네트워크 분할 허용성(Partitioning Tolerance)의 3가지 특성을 가지고 있다. CAP이론은 이 중 2가지만 만족할 수 있다는 이론이다. NoSQL은 대부분 이 CAP이론을 따른다.
일반적으로 RDBMS는 일관성과 가용성을 만족한다. NoSQL은 가용성과 네트워크 분할 허용성을 만족하는 제품군과 일관성과 분산허용을 만족하는 제품군으로 나눌 수 있다.
1. 일관성(Consistency): 분산된 노드 중 어느 노드로 접근하더라도 데이터 값이 같아야 한다.
일관성을 지원하지 않는 NoSQL을 사용한다면 동일한 데이터가 나타나지 않을 수 있다. 데이터의 변경을 시간의 흐름에 따라 여러 노드에 저나하기 때문이다. 이러한 방법을 최종적으로 일관성이 유지된다고 하여 최종 일관성 또는 궁극적 일관성을 지원한다고 한다.
각 NoSQL들은 분산 노드 간의 데이터 동기화를 위해서 두가지 방법을 사용한다.
첫째, 데이터 저장 결과를 클라이언트로 응답하기 전에 모든 노드에 데이터를 저장하는 동기식 방법을 사용한다.
그만큼 느린 응답시간을 보이지만 데이터의 정합성을 보장한다.
둘째, 메모리나 임시 파일에 기록하고 클라이언트에 먼저 응답한 다음, 특정 이벤트 또는 프로세스를 사용하여 노드로 데이터를 동기화하는 비동기식 방법이 있다.
빠른 응답시간을 보인다는 장점이 있지만, 쓰기 노드에 장애가 발생했을 경우 데이터가 손실될 수 있다.
2. 가용성(Availability): 클러스터링 된 노드 중 하나 이상의 노드가 실패되더라도 정상적으로 요청을 처리할 수 있는 기능을 제공한다. 가용성을 가진 NoSQL은 클러스터 내에서 몇 개의 노드가 망가지더라도 정상적인 서비스가 가능하다.
몇몇 NoSQL은 가용성을 보장하기 위해 데이터 복제를 사용한다. 동일한 데이터를 다중 노드에 중복 저장하여 그 중 몇 대의 노드가 고장나더라도 데이터가 유실되지 않도록 하는 방법이다. 데이터 중복 저장 방법에는 동일한 데이터를 가진 저장소를 하나 더 생성하는 Master-Slave 복제 방법과 데이터 단위로 중복 저장하는 Peer-to-Peer 복제 방법이 있다.
3. 네트워크 분할 허용성(Partitioning Tolerance): 클러스터링 노드 간에 통신하는 네트워크에 장애가 발생하더라도 정상적으로 서비스를 수행한다. 노드 간 물리적으로 전혀 다른 네트워크 공간에 위치해도 가능하다.
💡 여기서 지칭하는 "노드" 는 분산된 NoSQL 데이터베이스 서버 중 하나이다.
"클러스터링 된 노드" 는 네트워크를 통해 연결된 여러 대의 서버(노드)가 하나의 시스템처럼 작동하는 구성을 말한다.
저장방식에 따른 분류
Key-Value Model, Document Model, Column Model, Graph Model로 분류할 수 있다.

Key-Value Model

키와 값으로 이루어진 저장과 조회라는 가장 간단한 원칙에 충실한 모델이다.
고속 읽기와 쓰기에 최적화된 경우가 많다. key에 대한 단위 연산이 빠른 것이지, 여러 key에 대한 연산은 느릴 수 있다.
Value는 문자열이나 정수 같은 원시 타입이 들어갈 수도 있고, 또 다른 key-value가 들어갈 수도 있다. 이를 Column Family라고 하며, key 안에 (Column, Value) 조합으로 된 여러 개의 필드를 갖는 것을 말한다.
Key-Value Model의 key 값은 고유값으로 유지되어야 한다. 또한 테이블 간 조인을 고려하지 않으므로 RDB에서 관리하는 외부키나 컬럼별 제약 등이 필요 없다. value로 모든 데이터 타입을 허용하며, 그래서 개발자들이 데이터 입력 단계에서 검증 로직을 제대로 구현하는 것이 중요하다.
Key-Value Model은 간단한 데이터 모델을 대상으로 자주 읽고 쓰는 애플리케이션에 적합하다. 값은 단순한 원시 타입이 일반적이지만, 리스트나 json같이 구조화된 값도 가능하다.
ex) Redis, Riak, Oracle Berkely, AWS DynamoDB
Document Model

Key-Value의 확장된 형태로, value에 Document라는 타입을 저장한다.(Document는 구조화된 문서 데이터(XML, JSON 등)을 말한다.)
Document Model은 값을 문서로 저장한다.
Document id 또는 특정 속성값 기준으로 인덱스를 생성한다. 이 경우 해당 key 값의 range에 대한 효율적인 연산이 가능해지므로 이에 대한 쿼리를 제공한다. 따라서 Sorting, Join, Grouping이 가능해진다.
쿼리 처리에 있어서 데이터를 파싱해서 연산해야하므로 오버헤드가 key-value 모델보다 크다. 큰 크기의 document를 다룰 때는 성능이 저하된다.
각 문서별로 다른 필드를 가질 수 있으며, 따라서 개발자가 애플리케이션에서 데이터를 입력하는 단계에 컬럼과 필드의 관리가 제대로 이루어지도록 보장하는 것이 매우 중요하다.
예를 들어 필수 속성(Not Null 속성)에 대한 관리도 애플리케이션 레벨에서 관리가 이루어져야 한다.
주로 다음과 같은 목적으로 활용된다.
- 대용량 데이터를 읽고 쓰는 웹 사이트용 백엔드 지원
- 제품처럼 다양한 속성이 있는 데이터 관리
- 다양한 유형의 메타데이터 추적
- JSON 데이터 구조를 사용하는 애플리케이션
- 비정규화된 중첩 구조의 데이터를 사용하는 애플리케이션
다음은 MongoDB의 AirBnb DataSet의 일부이다.
{
"_id": "10006546",
"listing_url": "https://www.airbnb.com/rooms/10006546",
"name": "Ribeira Charming Duplex",
"summary": "Fantastic duplex apartment with three bedrooms, located in the historic area of Porto, Ribeira (Cube)...",
"house_rules": "Make the house your home...",
"property_type": "House",
"calendar_last_scraped": {
"$date": {
"$numberLong": "1550293200000"
}
},
"amenities": [
"TV",
"Cable TV",
"Wifi",
"Kitchen",
"Paid parking off premises",
"Smoking allowed",
"Microwave"
]
}
ex) MongoDB, CouchDB, Couchbase
Column Model
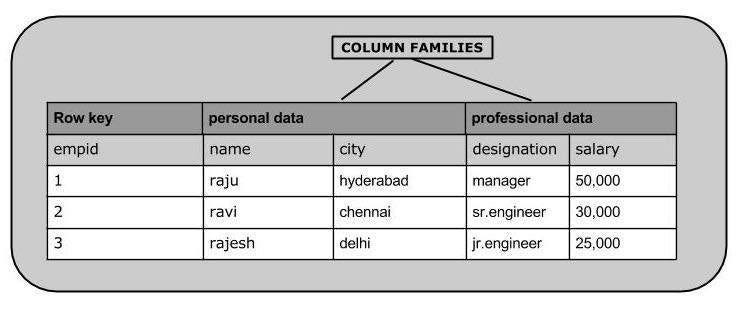
대용량 데이터, 읽기와 쓰기 성능, 고가용성을 위해 설계되었다. 구글에서 Big Table을 도입하고 페이스북은 Cassandra를 개발했다.
Column과 Row와 같이 관계형 데이터베이스와 동일한 용어를 쓰며 스키마를 정의한다. 컬럼 수가 많다면 관련된 컬럼들을 컬렉션으로 묶을 수 있다. 예를 들어 이름의 성과 이름을 하나로 묶고 사무실, 핸드폰 등의 전화번호들을 하나로 묶을 수 있다. 이렇게 묶인 컬럼들을 Column Family라고 한다.
Documnet Model과 마찬가지로 미리 정의된 스키마를 사용하지 않으므로 개발자가 데이터를 입력하는 시점에 원하는대로 칼럼을 추가할 수 있다.
테이블 간 조인을 지원하지 않는다.
관계형 데이터베이스에서는 한 객체에 대한 정보를 저장하기 위해 여러 테이블에 나누어 저장한다. 예를 들면 고객의 기본 정보 테이블(이름, 주소, 연락처)와 고객의 주문 정보 테이블 등을 나누어서 저장하고 조인을 통해 이 객체의 정보들을 활용한다.
Column Model은 일반적으로 비정규화되어 있으며 한 객체에 관련된 모든 정보는 정보를 가능한 매우 너비가 넓은 단일 row에 넣어서 보관한다. 따라서 한 row에 수백만개의 칼럼을 보관하는 경우도 비정상적인 것은 아니다.
Column Model은 여러 대로 구성된 클러스터에서 운영된다. 단일 서버에서 운영해도 될만큼 데이터가 적다면 Key-Value Model이나 Document Model을 고려하는 것이 나을 것이다.
다음과 같은 경우에 활용을 고려하면 좋다.
- 데이터베이스에 쓰기 작업이 많은 애플리케이션
- 지리적으로 여러 데이터 센터에 분산되어 있는 애플리케이션
- 복제본 데이터가 단기적으로 불일치하더라도 큰 문제가 없는 애플리케이션
- 동적 필드를 처리하는 애플리케이션
- 수백만 테라바이트 정도의 대용량 데이터를 처리할 수 있는 애플리케이션
ex) Hbase, Cassandra, GCP BigTable, Microsoft Cosmos DB
Graph Model

말 그대로 위 그림과 같이 그래프 형태로 저장하는 모델이다.
Node와 Edge로 이루어져 있는데 Node에는 Data Entity를 저장하며 Edge에는 Node간 관계를 저장한다.
일반적으로 Graph 시각화도 같이 있는 경우가 많고, 각 데이터들 간의 관계를 찾는데 특화되어 있다.
Graph Model은 노드 간 관계(Edge)를 따로 저장하는 만큼 각 데이터 간 관계를 저장하고 탐색하는데 특화되어 있다.
특색이 확실하여 소셜 네트워크 및 추천 엔진에서 자주 사용된다고 한다.
ex) Neo4j, Neptune