
Apache Kafka
- Apache Software Foundation의 Scalar 언어로 된 오픈 소스 메시지 브로커 프로젝트 즉, 메시지를 전달할 때 사용되는 서버이다.
- 링크드인(Linked-in)에서 개발, 2011년 오픈 소스화 되었다.
- 실시간 데이터 피드를 관리하기 위해 통일된 높은 처리량, 낮은 지연 시간을 지닌 플랫폼을 제공한다.
- Apple, Netflix, Kakao ... 등이 데이터 전달을 위해 Kafka 메시지 브로커를 사용하고 있다.
- Kafka 사용 이전

End-to-End 연결 방식의 아키텍처를 사용했다.
따라서 데이터 연동의 복잡성이 증가(HW, OS 등)했고 서로 다른 데이터 Pipeline 연결 구조를 가지다 보니 확장이 어려웠다.
- Kafka 사용 이후
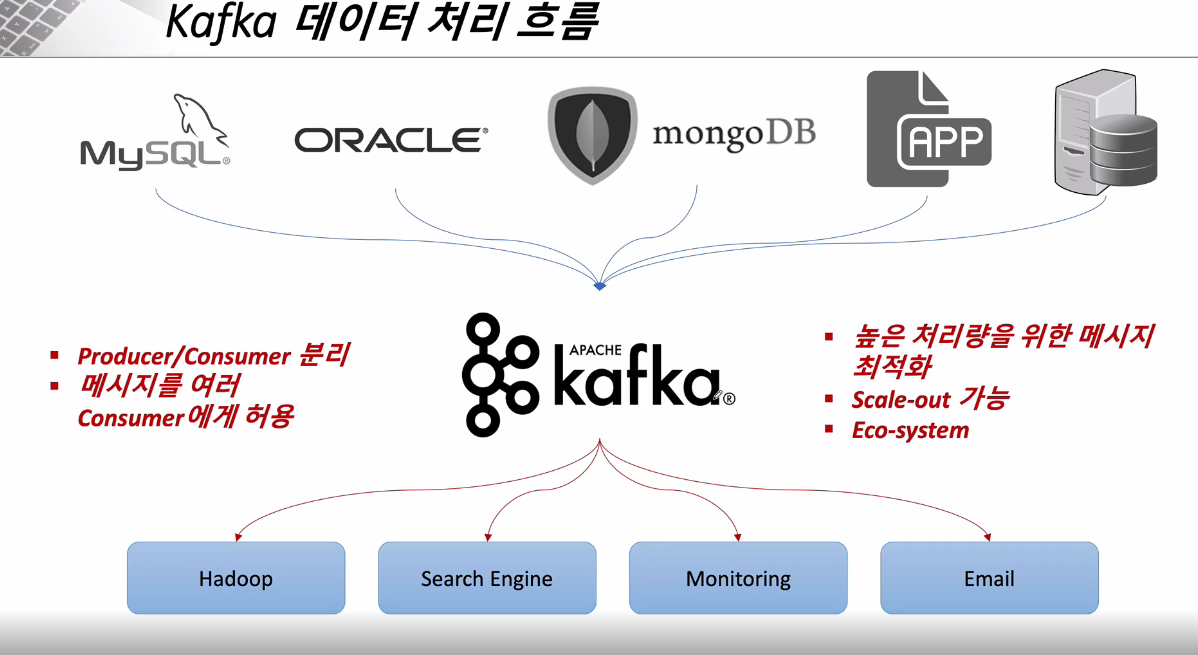
모든 시스템으로 데이터를 실시간으로 전송하여 처리가 가능해 졌으며, 데이터가 많아지더라도 확장이 용이하다.
- Kafka Broker
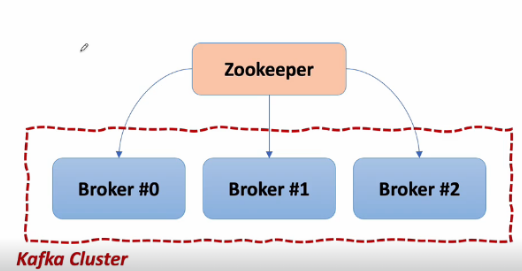
Kafka 애플리케이션 서버는 Broker 들로 이루어져 있다.
3대 이상의 Broker Cluster로 구성하는 것을 권장하며, 각 브로커끼리 상황 공유, 문제가 생겼을 때 대처 등을 위해 코디네이터(coordinator)를 사용하는데, 그 중 대표적인 Apache Zookeeper를 사용한다.
Zookeeper는 메타데이터(Broker ID, Controller ID 등)을 저장하고, 문제 발생 시 대처하는 등의 역할을 한다.
Broker 중 1대는 Controller 기능을 수행한다. Controller는 각 Broker 에게 담당 파티션 할당을 수행하고 다른 Broker들이 정상 동작하는지 모니터링 및 관리한다. Controller에게 문제가 생기면 Zookeeper가 Controller을 교체하는 등 조치를 취한다.
Apache Kafka 설치
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
- 버전 정보: Scala 2.13 - kafka_2.13-3.5.1.tgz (asc, sha512)
[중요한 폴더 정보]
1. config
server.properties(Kafka 서버에 사용), zookeeper.properties(Zookeeper에 사용)

2. bin
kafka와 Zookeeper등의 제어에 쓰이는 .sh 파일들이 있다. 윈도우는 이 안에 windows 폴더에 .bat 파일로 실행하면 된다.
Apache Kafka 사용
3대 이상을 사용하면 안정적이지만 우선 1대의 Kafka와 Zookeeper을 사용해 본다.
Kafka Client
Kafka Client를 활용해 테스트해본다. kafka client는 java library 가 있어서 의존성만 추가해줘도 된다.
https://mvnrepository.com/artifact/org.apache.kafka/kafka-client
또한, Producer(메시지를 보냄), Consumer(메시지를 받음) 등의 Kafka 관련 API도 제공되고, C/C++, Node.js 같은 언어에 대한 3rd party library 도 존재한다.

메시지를 보내면 Topic이라는 곳에 기본적으로 저장된다. Topic은 임의로 생성할 수 있으며 Producer가 해당 Topic으로 메시지를 보내게 된다. 다른 Producer가 같은 Topic으로 메시지를 보낼 수도 있고 Producer는 기존에 메시지를 보낸 Topic이 아닌 다른 Topic으로 메시지를 보낼 수 있다. Consumer은 등록한 Topic에서 전달된 메시지를 일괄적으로 전달받는다. 따라서 Producer과 Consumer는 Topic을 통해서만 메시지를 주고 받기 때문에 서로에게 의존하지 않아도 된다.
직접 Kafka 서버와 Zookeeper를 기동해서 사용해보자. cmd 창은 Zookeeper, Kafka 서버에 하나씩 Producer, Consumer에 하나씩 총 4개를 켜놓아야 한다. 모든 명령은 Kafka 설치 경로에서 이루어진다.
windows는 bin>windows 에 Kafka 실행 명령어가 저장되어 있음에 주의한다.
# Version 확인
bin\windows\kafka-topics.bat --version
# Zookeeper 실행
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
# Kafka 실행
bin\windows\kafka-server-start.bat config\server.properties
# Topic 생성
bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --topic stock-update
# Topic 생성 - partitions, replication-factor
bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --topic stock-update --partitions 1 --replication-factor 1
# Topic 확인
bin\windows\kafka-topics.bat --describe --bootstrap-server localhost:9092 --topic stock-update
# Topic 목록
bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
# Topic 삭제
bin\windows\kafka-topics.bat --delete --bootstrap-server localhost:9092 --topic stock-update
# Producer
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic stock-update
# Producer - Key, Value
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic stock-update --property "parse.key=true" --property "key.separator=:" --property "print.key=ture"
# Producer - Message
ABCDE
# Producer - Key, Value Message
key:{"val1":"A","val2":"B","val3":3}
# Consumer
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic stock-update --from-beginning
# Consumer Group 확인
bin\windows\kafka-consumer-groups.bat --list --bootstrap-server localhost:9092
# Consumer Group Topic 확인
bin\windows\kafka-consumer-groups.bat --describe --bootstrap-server localhost:9092 --group stock-update-group1. Zookeeper 구동
기본 port: 2181
bin\windows\zookeeper-server-start.bat config\zookeeper.properties[오류 해결]
"입력 명령어 줄이 너무 깁니다." 오류가 떴다.
최대한 root에 가깝게 Kafka 위치를 바꿨더니 해결됐다.
2. Kafka Server 구동
기본 port: 9092
bin\windows\kafka-server-start.bat config\server.properties3. Topic 생성
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --create --topic quickstart-events --partitions 1이름은 quickstart-events 로 설정함.
4. Producer 실행
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic quickstart-events5. Consumer 실행
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning

--> 한글이라 다 깨져서 나오는 듯 하지만 Producer에서 보낸 메시지가 Consumer로 잘 전달됨을 알 수 있다.
오타가 좀 열받게 나네
Producer가 Consumer에게 직접 메시지를 전달하는 것이 아니라, Topic에 등록한 Consumer에게만 메시지가 전달됨을 알 수 있다.
Kafka Connect

이전에는 코드 등을 이용해서 각 서비스들끼리 Client가 되어 Prod/Cust 구조로 메시지를 공유했다. 이제 Connect 를 통해 Source System에서부터 Data를 Import 해 Target System으로 Data를 Export 할 수 있다.
즉, 코드 없이 Configuration 만으로 데이터를 이동할 수 있다.
Standalone 혹은 Distribution 모드로 작동할 수 있다. 데이터는 RESTful API 를 통해 Stream 혹은 Batch 형태로 전송할 수 있고, 커스텀 Connector를 통해 다양한 Plugin 을 제공한다.
order-service 에 MySQL을 연동시켜 Connect 동작을 시켜볼 것이다.
order-service의 pom.xml에 MySQL 연동을 위한 의존성을 추가한다.
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>windows 환경의 경우 mysql.server start가 아닌 net start mysql을 해주어야 한다.
[오류 해결]
net start mysql을 입력하니
"서비스 이름이 잘못되었습니다.
NET HELPMSG 2185을(를) 입력하면 도움말을 더 볼 수 있습니다."
이런 오류가 떴다.
일단 관리자 권한으로 실행하고 mysqld -install을 입력해준다. 다시 net start mysql을 입력하면 아래와 같은 오류가 뜬다.

port 충돌 오류였다.
충돌하는 port 중지하고 실행하니 잘 된다.
https://humahumahuma.tistory.com/285
윈도우10 APM 설치시 'MySQL 서비스를 시작할 수 없습니다'
C:\WINDOWS\system32>net start mysql MySQL 서비스를 시작합니다... MySQL 서비스를 시작할 수 없습니다. 서비스가 오류를 보고하지 않았습니다. NET HELPMSG 3534을(를) 입력하면 도움말을 더 볼 수 있습니다. MySQL
humahumahuma.tistory.com
--> 근데 이 오류인지 모르고 data 폴더도 날리고 초기화 명령어도 때려서 후에 mysql을 사용할 때 오류가 터질까봐 조금 무섭다
[오류 해결]
mysql 비밀번호 까먹었다.
재설정으로 1234 로 바꿨다.
https://kukuta.tistory.com/248
[MySQL] root 패스워드 분실 시 리셋 방법
만일 여러분이 한번도 MySQL root 계정의 패스워드를 설정한적이 없다면 root로 접속 할 때 패스워드를 묻지 않습니다. 패스워드를 설정하지 않으면 매번 접속 할 때 마다 귀찮게 패스워드를 묻지도
kukuta.tistory.com
다시 돌아와서, mysql에 접속하고 mysql -uroot -p 를 입력하여 비밀번호까지 입력한 다음, mydb table을 생성한다.
discovery-service, apigateway-service, order-service를 차례대로 실행하고 h2-console을 확인한다.
다음과 같이 바꿔주고 user name엔 root, 비밀번호엔 아까 설정한 1234 를 입력한다.
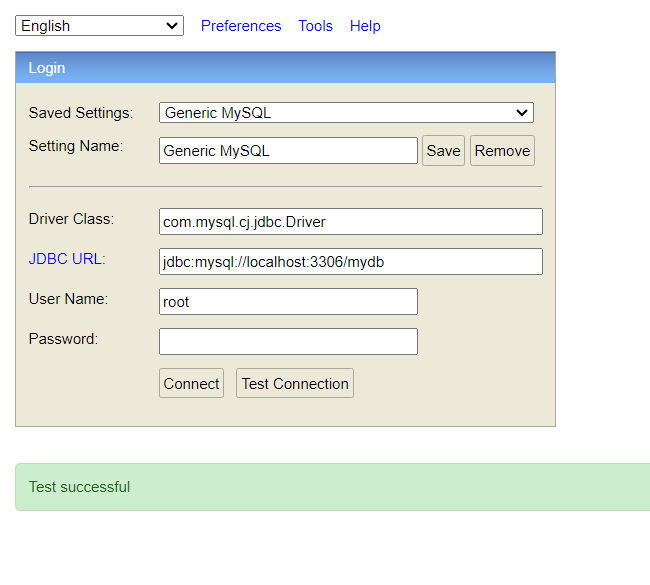
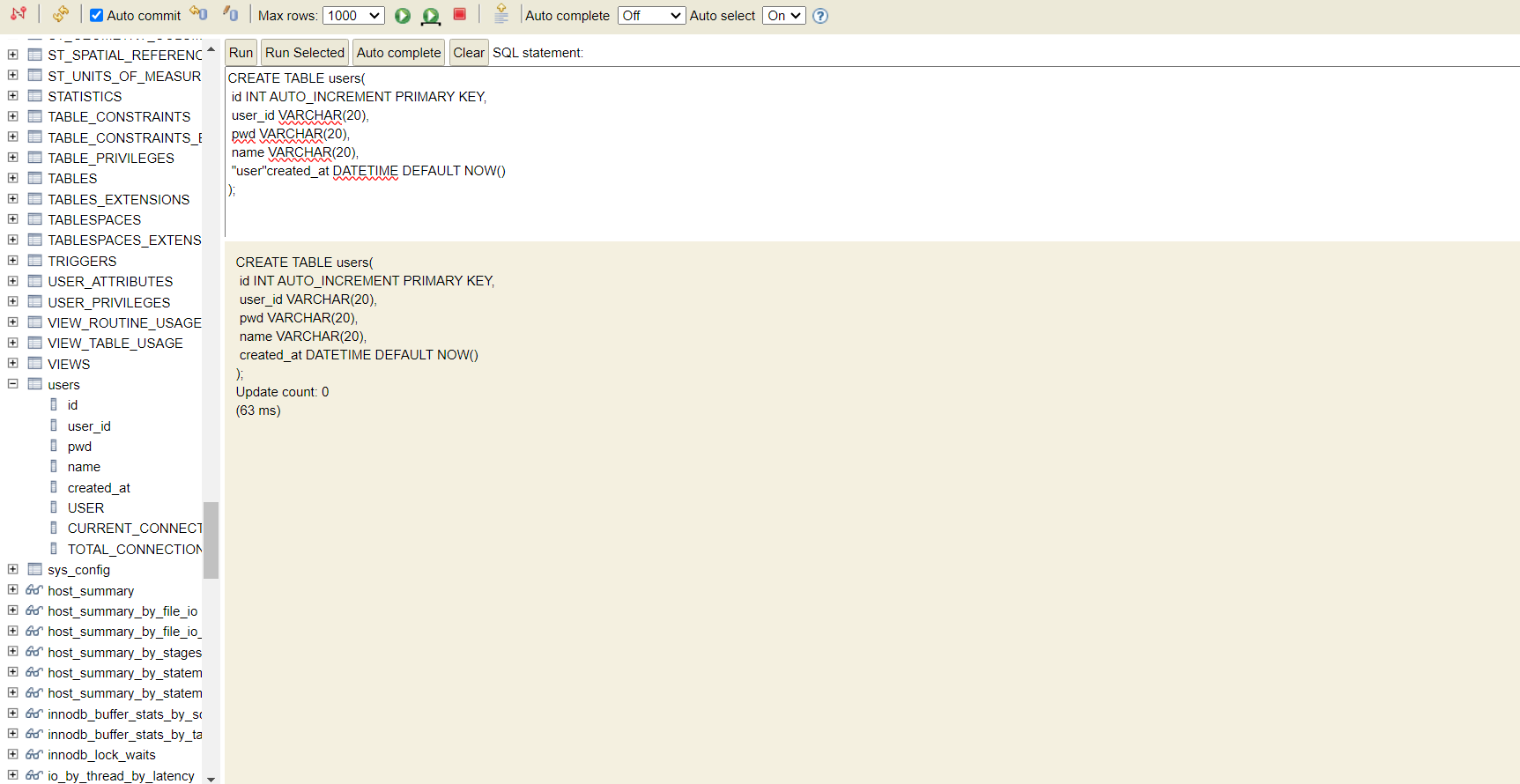
mydb에 users table까지 생성 완료(그런데 저만 mydb에 파일 조낸 많나요?)
Kafka Connection
http://packages.confluent.io/archive/7.4/confluent-community-7.4.0.tar.gz
- 버전 정보: 7.4
--> 강사님처럼 curl -O http://packages.confluent.io/archive/7.4/confluent-community-7.4.0.tar.gz 명령어 쓰려고 하니까 permisson denied 뜬다. 그냥 직접 링크 이동해서 다운로드 했다.
tar xvf confluent-community-7.4.0.tar.gz
--> cmd에 해당 압축 해제 명령을 하니 tar: Error exit delayed from previous errors. 이런 오류가 떠서 해제가 안된건가 싶었는데 해당 폴더로 이동하니 압축 해제가 되어 있었다. 혹시 나중에 오류가 생길까봐 ignore 명령어도 안썼는데 아무튼 된거 같다.
[참고]
-tar.gz 압축풀기
tar -xvzf (압축파일명).tar.gz
--> 이 방법을 시도해 해제하려고 했는데, 혹시 계속 문제가 생긴다면 xvf말고 xvzf 사용해보길

Kafka connect를 실행해 보자. Zookeeper와 Kafka는 실행되고 있는 상태여야 한다.
bin\windows\connect-distributed.bat etc\kafka\connect-distributed.properties
[오류 해결]
강의에서 나온 오류가 아니라 아래와 같은 오류가 떴다.
Error: Could not find or load main class org.apache.kafka.connect.cli.ConnectDistributed
Caused by: java.lang.ClassNotFoundException: org.apache.kafka.connect.cli.ConnectDistributed
안녕하세요!! connector 실행시 오류가 생겨 질문 드립니다. - 인프런 | 질문 & 답변
D:\\KAFKA_HOME\\confluent-6.1.0>.\\bin\\windows\\connect-distributed.bat .\\etc\\kafka\\connect-distributed.properties[2021-06-10 15:43:28,943] WARN ...
www.inflearn.com
이 해결 방법을 사용하기 전에 또 다른 오류가 발생했다. 배치 파일이 열리지 않고 켜지자마자 down된다.
아마 win 10 os를 사용한다면 백신 문제일 가능성이 크다 한다.
McAfee LiveSafe 아마도 이 프로그램 때문인 것 같아 삭제하고 다시 하려 한다.
이더리움 채굴 배치파일이 바로 꺼진다면?
이더리움 피닉스 마이너 채굴 화면 꺼짐 오류 현상, 해결방법 이 블로그는 게재된 광고수익으로 운영됩니다. 정보가 도움이 되었다면 글쓴이에게 음료 한잔의 여유를 부탁드립니다. 가상화폐
dongdinolife.tistory.com
--> 결론은 보안 프로그램도 다 지워봤는데 배치 파일이 안열렸다.
인프런 방법대로 수정하려면 배치 파일 내부를 수정해야 한다.
혹시 하는 마음에 빈 메모장에 배치 파일을 드래그 했더니 수정이 가능하다!
저처럼 개고생하지 마시고 윈도우 사용자들은 오류가 발생했다면 빈 메모장에 .bat 드래그하고 수정하길

Kafka Connect 연결을 확인하고 Topic list를 다시 확인하면 이전에 없던 Topic들이 생성된 것을 볼 수 있다.

Connector 가 MySQL와 연동되어야 하기 때문에 JDBC Connector 가 추가로 필요하다. 다음 URL에 접속해 Download를 누른다.
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
JDBC Connector (Source and Sink)
Confluent, founded by the original creators of Apache Kafka®, delivers a complete execution of Kafka for the Enterprise, to help you run your business in real-time.
www.confluent.io
--> 실제 우리가 필요로 하는 파일이다.
1. plugin.path 수정
confluent-7.4.0/etc/kafka/connect-distributed.properties 를 VS Code 로 열어서 plugin.path 값이 있을 것이다. 여기에 원래 값 대신 조금 전에 다운로드받은 파일의 경로를 지정할 것이다.
plugin.path=C:\confluentinc-kafka-connect-jdbc-10.7.4\lib2. mysql 라이브러리 복사
\.m2\repository\com\mysql\mysql-connector-j\8.0.33>
--> 이 경로로 이동해서 필요한 파일을 확인한다. 여기 있는 파일 중 jar 파일을 Connector 가 쓸 수 있도록 Connector의 영역에 복사해 줄 것이다.
copy mysql-connector-j-8.0.33.jar C:\confluent-7.4.0\share\java\kafka
Kafka Source Connect 사용
MySQL에서 변경이 일어나면 Kafka Cluster에게 전해주는 Source Connect를 기동하고 사용해보자.
다음 명령어로 Source Connect를 기동한다.
bin\windows\connect-distributed.bat etc\kafka\connect-distributed.properties
[오류 해결]
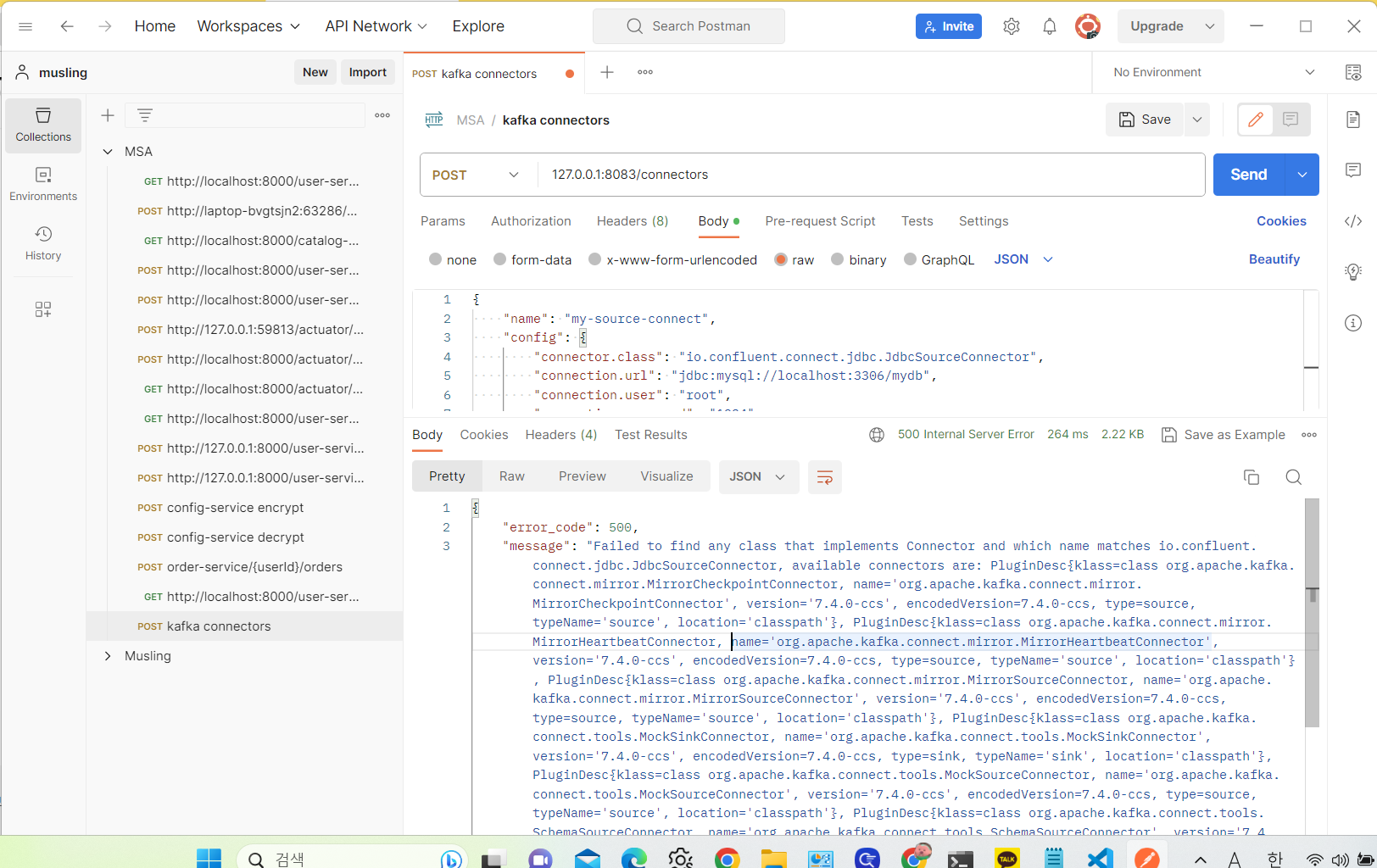
분명 plugin.path 에 jdbc 경로를 지정해 줬는데 인식을 못한다.
http://localhost:8083/connector-plugins--> 해당 경로로 사용할 수 있는 플러그인 정보를 확인해 보니 JDBC 관련 플러그인 목록이 확인이 안된다.
알고보니 windows는 경로 지정 시 \ 하나가 더 붙어야 한다고 한다. (개같은 윈도우)
plugin.path=\C:\\confluentinc-kafka-connect-jdbc-10.7.4\\lib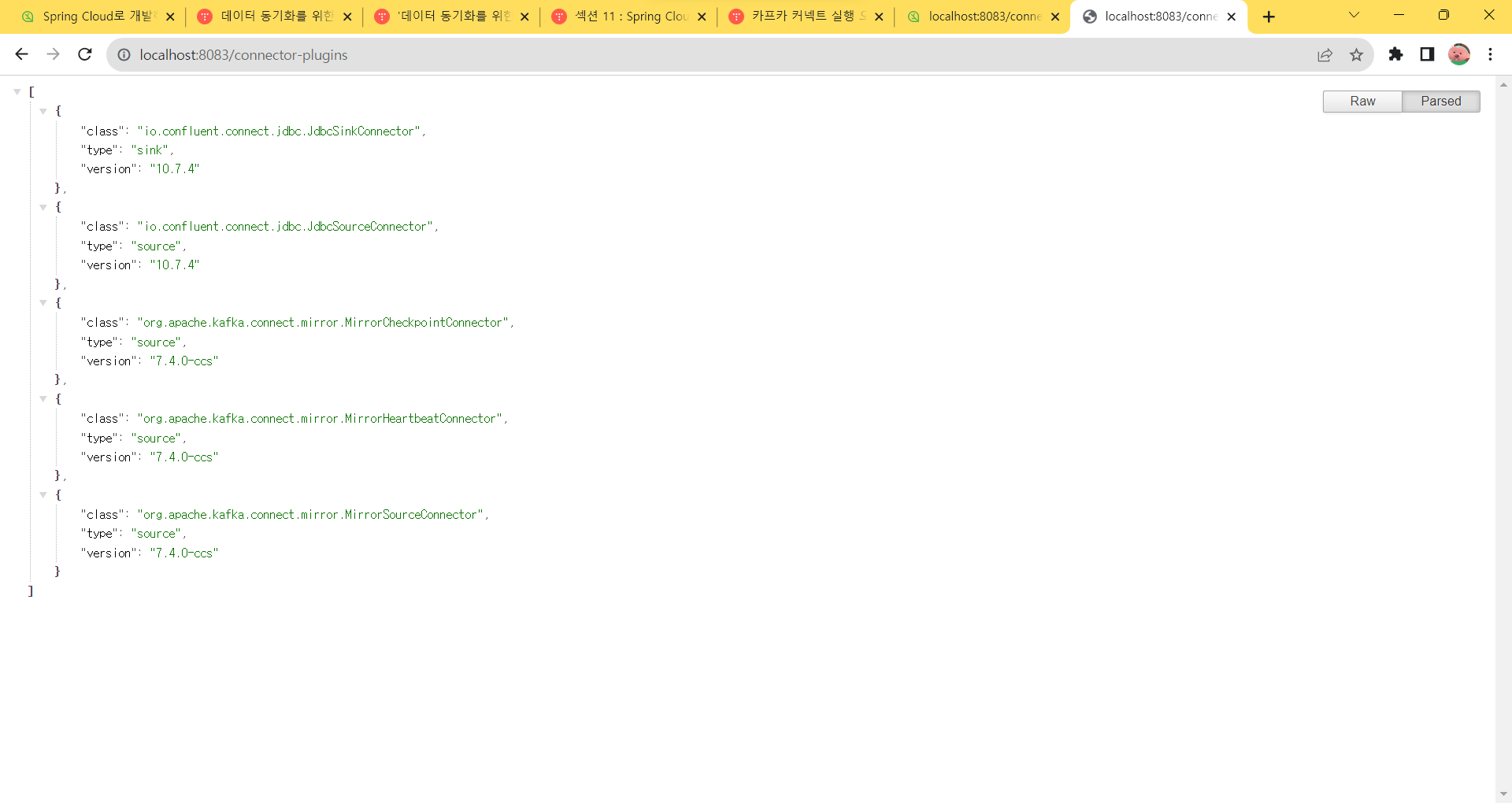
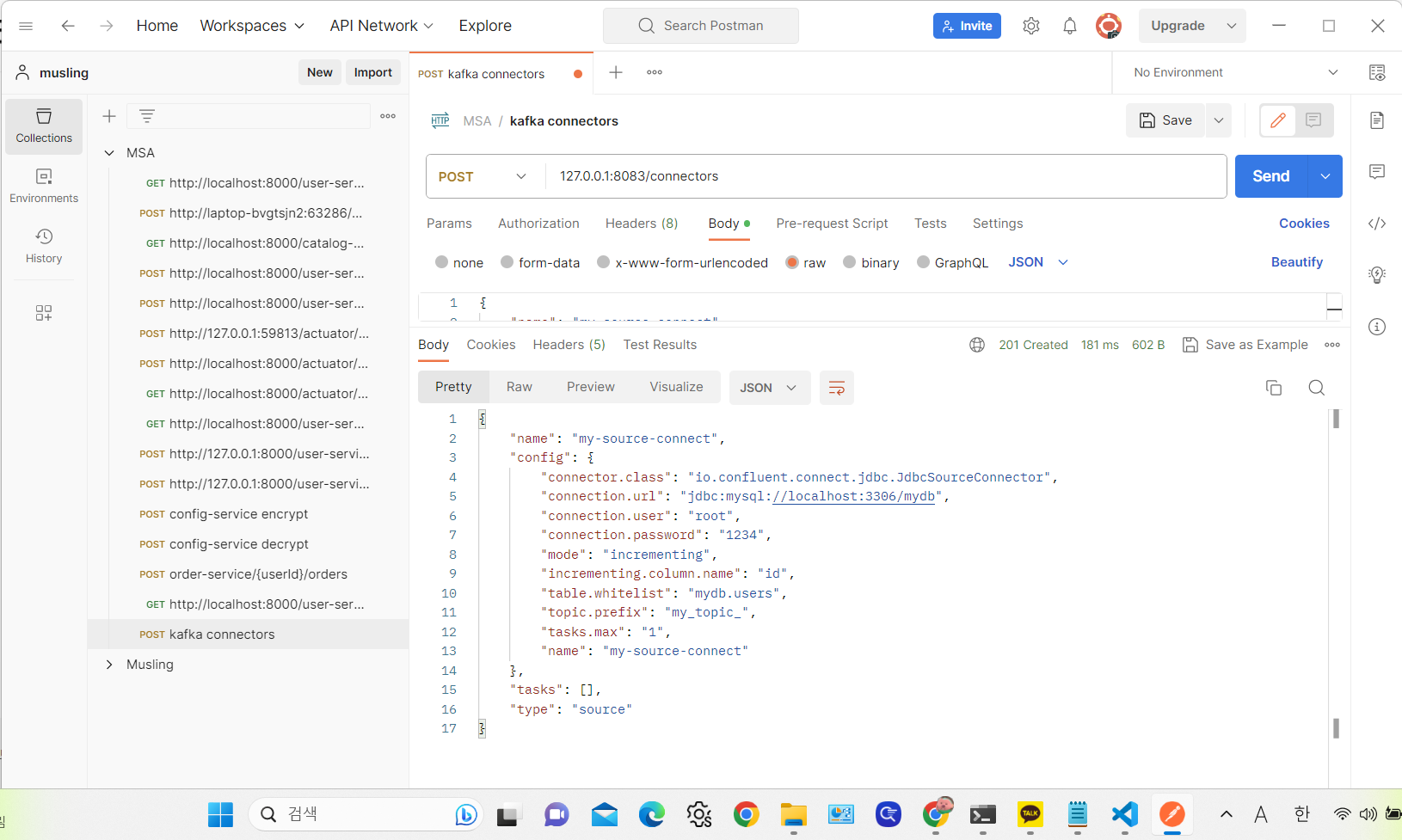
그리고 내 mydb 안에 있는 users 데이터베이스에서 변경이 일어나면 알아차리는 Topic을 생성하자. RESTful API 로 할 수 있어서 Postman을 활용해 등록하면 된다.
{
"name": "my-source-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"connection.user": "root",
"connection.password": "1234",
"mode": "incrementing",
"incrementing.column.name": "id",
"table.whitelist": "mydb.users",
"topic.prefix": "my_topic_",
"tasks.max": "1"
}
}
--> 여기서 Topic은 prefix 이름에 실제 이름를 더한 것이다. 이 경우 my_topic_users 가 된다.
--> topic.whitelist 에는 우리의 경우 테이블 이름을 써야 하는데, 그냥 user라고 쓰면 다른 데이터베이스의 테이블과 구분하지 못해 mydb.users와 같이 db.table 형식으로 써야 한다.
https://www.inflearn.com/questions/618181/source-connector-%EC%98%A4%EB%A5%98
Source Connector 오류 - 인프런 | 질문 & 답변
- 학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!- 먼저 유사한 질문이 있었는지 검색해보세요.- 서로 예의를 지키며 존중하는 문화를 만들어가요.- 잠깐! 인프런 서비스 운영 관련 문
www.inflearn.com
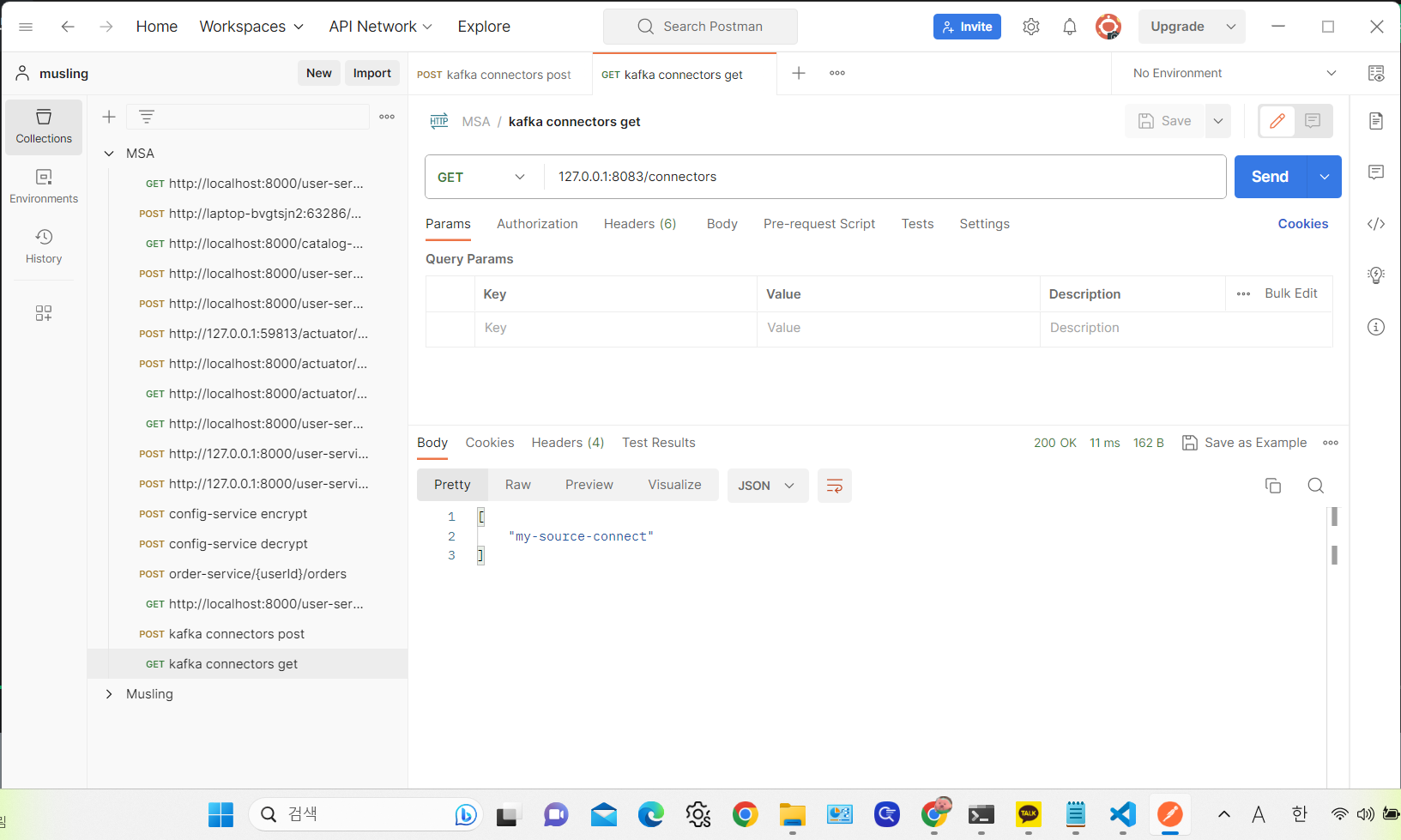
get 방식으로 호출하면 현재 등록된 connector 정보를 확인할 수 있다.
[오류 해결]

mydb.users로 해결된 줄 알았는데 아니었다.
kafka connect log를 보니 인증 오류 같았다.
알고보니 mysql 8.0 부터 RSA 보안을 사용하지 않으면 오류가 난다고 한다.
https://kogle.tistory.com/87#comment15369241
MySql : MySql 8.0이상 caching_sha2_password authentication plugin 문제해결
1. MySql 8.0은 SHA-256 hashing을 구현하는 두 가지 인증 플러그인을 지원한다. 1-1 sha256_password - 기본적인 SHA-256 인증을 구현한 플러그인 1-2 caching_sha2_password - sha256_password와 동일한데 성능 향샹을 위해
kogle.tistory.com
ALTER USER 'yourusername'@'localhost' IDENTIFIED WITH mysql_native_password BY 'youpassword';--> mysql 접속해서 해당 명령어 입력하고 다시 postman get 요청을 보내봤더니 성공했다.

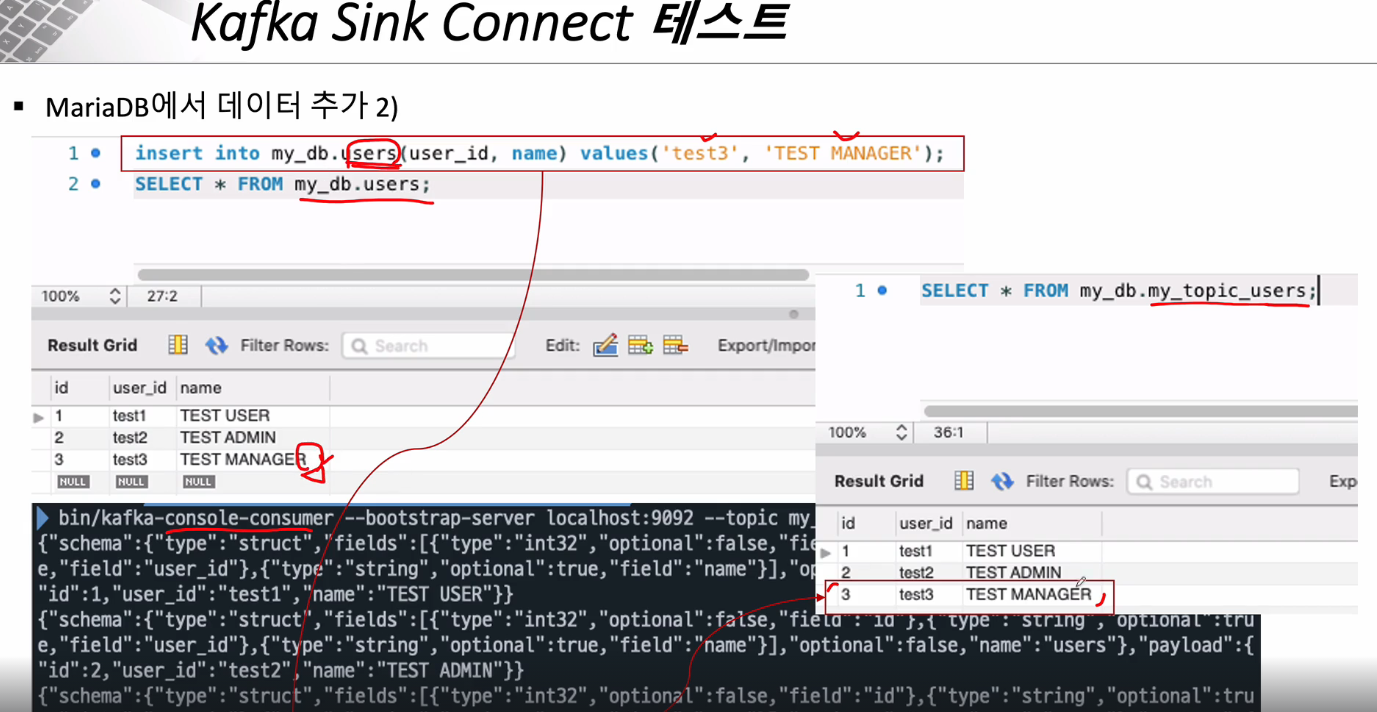
변경이 있어야 Connector가 Topic을 자동으로 만들어주기 때문에 db에 다음과 같이 데이터를 삽입한다.


--> connector과 연결한 users table에 변동점이 생겼으므로 my_topic_users 라는 Topic이 생성된 것을 볼 수 있다.
Consumer을 생성해 테스트를 진행해 본다.
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic my_topic_users --from-beginning
데이터베이스 입력에 대한 JSON 파일이 나온다.
실제로 테이블의 정보들이 들어있어, 데이터를 전달 받은 쪽에서 똑같은 데이터를 데이터베이스에 넣을 수 있도록 되어 있다.

--> 테스트용으로 db에 데이터를 하나 더 생성하니 자동으로 Topic에 정보가 반영됨을 알 수 있다.
Json 형식의 위 값을 사용하게 되면 db에 직접 자료를 넣지 않더라도 Topic에 값을 전달하게 되면 그 값이 db에 반영된다.
이를 도와주는 것이 kafka sink connect 이다.
Kafka Sink Connect 사용
Sink Connect의 역할은 Topic에 전달된 데이터를 가져와서 사용하는 것이다.
따라서 Sink Connect와 연결될 Topic은 "topics" 에 지정하면 된다.
테스트를 위해선 Zookeeper, Kafka Server, Connector, Consumer가 띄워져 있는 상태여야 한다.
[오류 해결]
Kafka Sink Connect를 추가해야 하는데
"error_code": 400, "message": "Connector configuration is invalid and contains the following 4 error(s):\nQuery mode must be specified\nQuery mode must be specified\nQuery mode must be specified\nQuery mode must be specified\nYou can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`" }
이런 오류가 떴다. 400 bad request인 걸 봐선 요청에 뭔가 누락되었거나 오타인 것 같은데 아무리 봐도 오타는 아니다.
알고보니 요청에 "mode" 가 누락된 것이었다. 강사님은 강의에서 "mode" 를 따로 지정하지 않는데 오류가 뜨는 이유를 잘 모르겠다.
Kafka Connect JDBC 소스 커넥터의 설정에는 `mode`라는 속성이 필요하며, 이는 데이터베이스로부터 데이터를 가져오는 방식을 나타냅니다. 당신이 제출한 구성에서 이 `mode`가 누락되었습니다. 이로 인해 위의 오류 메시지가 발생한 것입니다.
`mode` 설정은 다음과 같은 옵션들을 가질 수 있습니다:
1. `bulk`: 데이터베이스의 모든 행을 한 번에 가져옵니다.
2. `incrementing`: 단일 증가 컬럼을 기반으로 새로운 또는 수정된 행을 가져옵니다.
3. `timestamp`: 단일 타임스탬프 컬럼을 기반으로 새로운 또는 수정된 행을 가져옵니다.
4. `timestamp+incrementing`: 타임스탬프와 증가 컬럼을 결합하여 새로운 또는 수정된 행을 가져옵니다.
`incrementing`, `timestamp`, 또는 `timestamp+incrementing` 모드를 사용하는 경우, 해당 모드와 관련된 추가 설정이 필요할 수 있습니다. 예를 들면, `incrementing.column.name` 또는 `timestamp.column.name`과 같은 설정입니다.
따라서, 당신의 구성을 수정하려면 원하는 모드에 따라 `mode` 속성을 추가해야 합니다. 예를 들어, `incrementing` 모드를 사용하려는 경우 다음과 같이 구성을 수정할 수 있습니다:
```json
{
"name": "my-sink-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"connection.user": "root",
"connection.password": "1234",
"mode": "incrementing",
"incrementing.column.name": "id",
"auto.create": "true",
"auto.evolve": "true",
"delete.enabled": "false",
"tasks.max": "1",
"topics": "my_topic_users"
}
}
```
여기서 `incrementing.column.name`는 증가하는 값을 가지는 데이터베이스의 컬럼 이름을 나타냅니다. 이 컬럼은 해당 테이블의 기본 키나 유니크한 값을 가져야 합니다.
--> 마땅히 구글링 결과가 안나와서 chatGPT한테 물어본 결과이다.
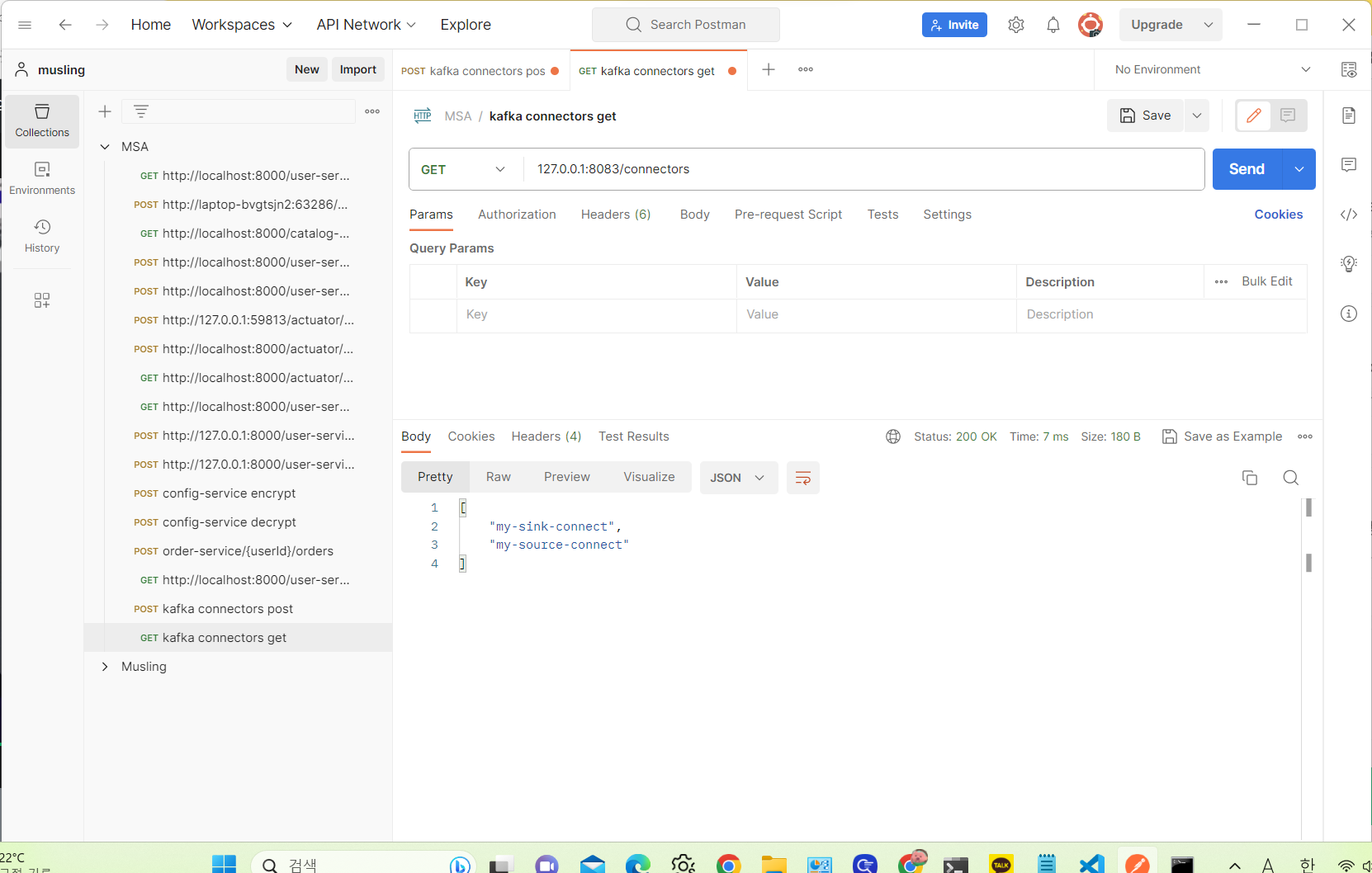
--> 아무튼 connect가 추가된 것을 확인했다.
정상적으로 추가가 되었다면 auto.create 설정으로 db에 Topic과 같은 이름으로 table이 추가되어야 한다.
그런데 table이 보이지 않는다.
당연하다. 내가 connector.class 를 잘못 지정해 줬기 때문이다. JdbcSourceConnector 로 지정해 놨는데 sink connect를 사용하려면 io.confluent.connect.jdbc.JdbcSinkConnector 를 사용해야 한다.
(계속 누락된 option이 있다길래 뭔가 했다. 당연히 누락된 거겠지)


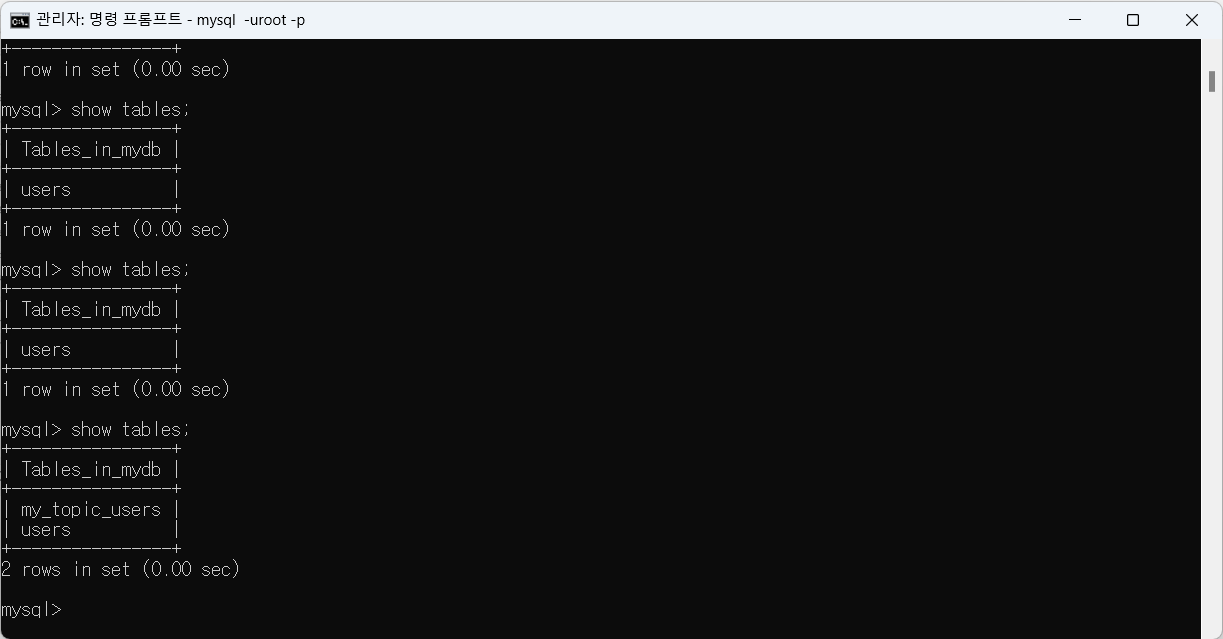
--> auto.create로 Topic 이름과 같은 테이블이 자동 생성된 것을 알 수 있다.
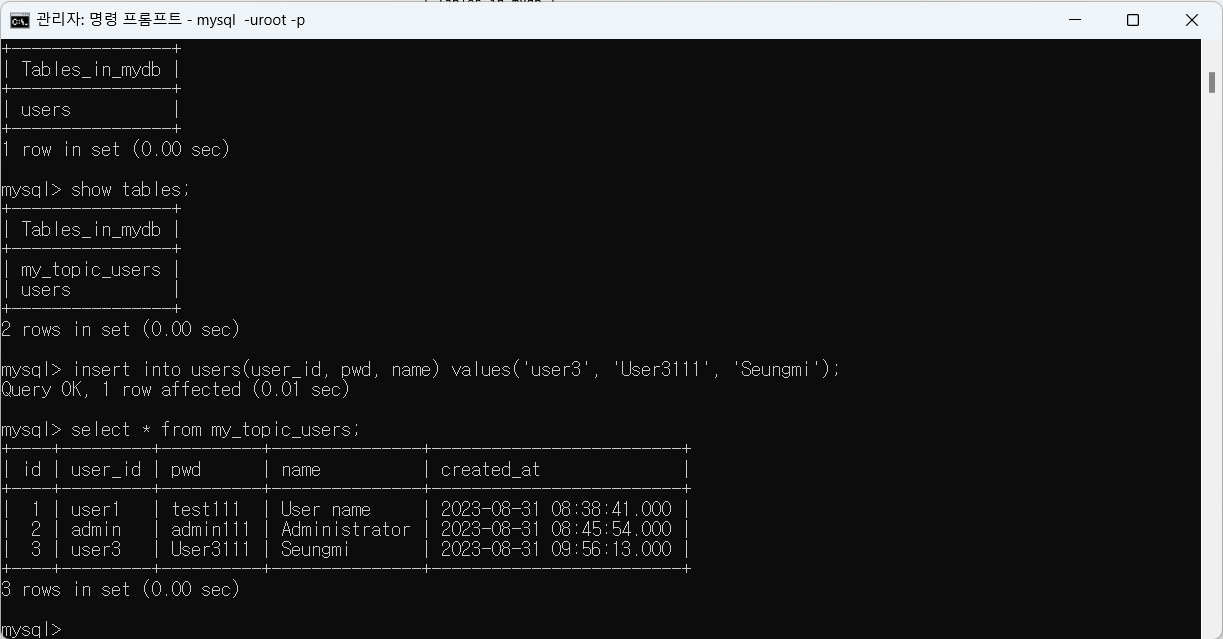
--> users 에 데이터를 삽입해도 다른 테이블에 동기화 됨을 알 수 있다.
우리가 목표로 한 Sink Connect가 완벽히 이루어졌다.
마지막으로, 직전에 Consumer로 테스트 했을 때, JSON 형식으로 데이터를 잘 삽입할 수 있도록 가공되어 주어진다고 했다. 이걸 Producer 입장에서 그대로 Sink Connector 가 연결된 Topic에 보내본다.
Producer을 하나 생성해 보자.
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic my_topic_users{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"string","optional":true,"field":"user_id"},{"type":"string","optional":true,"field":"pwd"},{"type":"string","optional":true,"field":"name"},{"type":"int64","optional":true,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"created_at"}],"optional":false,"name":"users"},"payload":{"id":4,"user_id":"my_id","pwd":"my_pwd","name":"stopmsa","created_at":1693478873000}}
--> 이런 json format을 보내면 되는데 우리는 이 중에서 payload 부분을 임의로 수정해 보낼 것이다.
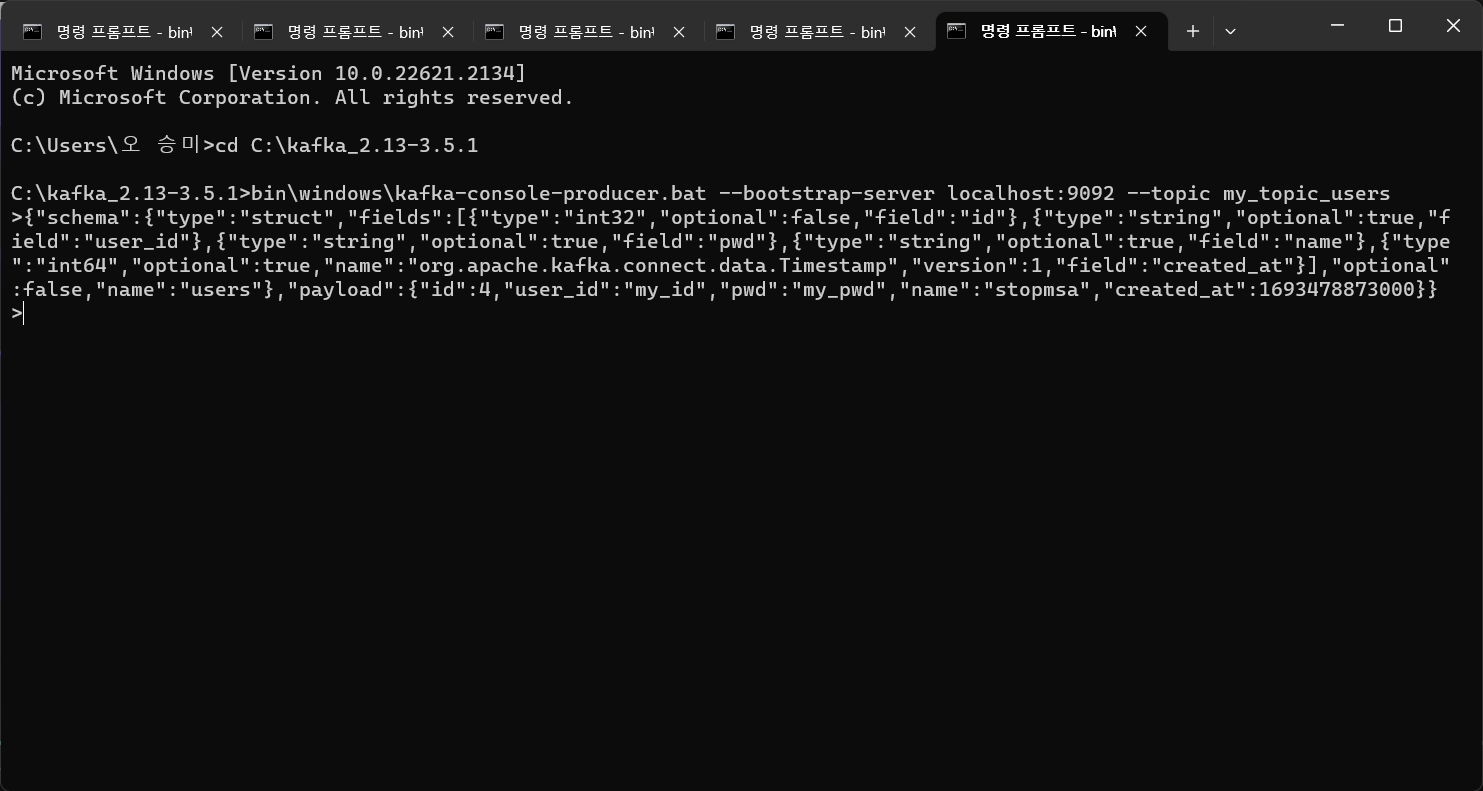

Producer가 보낸 값을 my_topic_users Topic을 사용하는 Consumer가 잘 받아왔음을 확인할 수 있다.
이 때 db의 users table을 확인해 보면 방금 Producer가 보낸 값이 반영이 되어 있지 않다.
users는 Topic으로부터 데이터를 가져오지 않고 자신의 데이터를 Topic에 밀어넣는 기능을 하기 때문인데 반면에 sink connect와 연결되어 있는 my_topic_users 는 데이터가 반영되어 있음을 알 수 있다.

이제 우리는 Kafka를 통해 기존에 만들었던 user, order 등의 service에 데이터 동기화 시키는 작업을 다음 섹션부터 진행해 볼 것이다.
+ 서버를 종료시킬 땐 ctrl+c 로 일괄 종료시키도록 하자.
할 수 있는 오류는 다 겪어본듯 슈발
'개발 > MSA' 카테고리의 다른 글
| 데이터 동기화를 위한 Apache Kafka의 활용 ② (0) | 2023.09.07 |
|---|---|
| 마이크로서비스간 통신 (0) | 2023.08.18 |
| 설정 정보의 암호화 처리 (0) | 2023.08.18 |
| Spring Cloud Bus (0) | 2023.08.11 |
| Configuration Service (0) | 2023.08.10 |
Apache Kafka
- Apache Software Foundation의 Scalar 언어로 된 오픈 소스 메시지 브로커 프로젝트 즉, 메시지를 전달할 때 사용되는 서버이다.
- 링크드인(Linked-in)에서 개발, 2011년 오픈 소스화 되었다.
- 실시간 데이터 피드를 관리하기 위해 통일된 높은 처리량, 낮은 지연 시간을 지닌 플랫폼을 제공한다.
- Apple, Netflix, Kakao ... 등이 데이터 전달을 위해 Kafka 메시지 브로커를 사용하고 있다.
- Kafka 사용 이전
End-to-End 연결 방식의 아키텍처를 사용했다.
따라서 데이터 연동의 복잡성이 증가(HW, OS 등)했고 서로 다른 데이터 Pipeline 연결 구조를 가지다 보니 확장이 어려웠다.
- Kafka 사용 이후
모든 시스템으로 데이터를 실시간으로 전송하여 처리가 가능해 졌으며, 데이터가 많아지더라도 확장이 용이하다.
- Kafka Broker
Kafka 애플리케이션 서버는 Broker 들로 이루어져 있다.
3대 이상의 Broker Cluster로 구성하는 것을 권장하며, 각 브로커끼리 상황 공유, 문제가 생겼을 때 대처 등을 위해 코디네이터(coordinator)를 사용하는데, 그 중 대표적인 Apache Zookeeper를 사용한다.
Zookeeper는 메타데이터(Broker ID, Controller ID 등)을 저장하고, 문제 발생 시 대처하는 등의 역할을 한다.
Broker 중 1대는 Controller 기능을 수행한다. Controller는 각 Broker 에게 담당 파티션 할당을 수행하고 다른 Broker들이 정상 동작하는지 모니터링 및 관리한다. Controller에게 문제가 생기면 Zookeeper가 Controller을 교체하는 등 조치를 취한다.
Apache Kafka 설치
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
- 버전 정보: Scala 2.13 - kafka_2.13-3.5.1.tgz (asc, sha512)
[중요한 폴더 정보]
1. config
server.properties(Kafka 서버에 사용), zookeeper.properties(Zookeeper에 사용)
2. bin
kafka와 Zookeeper등의 제어에 쓰이는 .sh 파일들이 있다. 윈도우는 이 안에 windows 폴더에 .bat 파일로 실행하면 된다.
Apache Kafka 사용
3대 이상을 사용하면 안정적이지만 우선 1대의 Kafka와 Zookeeper을 사용해 본다.
Kafka Client
Kafka Client를 활용해 테스트해본다. kafka client는 java library 가 있어서 의존성만 추가해줘도 된다.
https://mvnrepository.com/artifact/org.apache.kafka/kafka-client
또한, Producer(메시지를 보냄), Consumer(메시지를 받음) 등의 Kafka 관련 API도 제공되고, C/C++, Node.js 같은 언어에 대한 3rd party library 도 존재한다.
메시지를 보내면 Topic이라는 곳에 기본적으로 저장된다. Topic은 임의로 생성할 수 있으며 Producer가 해당 Topic으로 메시지를 보내게 된다. 다른 Producer가 같은 Topic으로 메시지를 보낼 수도 있고 Producer는 기존에 메시지를 보낸 Topic이 아닌 다른 Topic으로 메시지를 보낼 수 있다. Consumer은 등록한 Topic에서 전달된 메시지를 일괄적으로 전달받는다. 따라서 Producer과 Consumer는 Topic을 통해서만 메시지를 주고 받기 때문에 서로에게 의존하지 않아도 된다.
직접 Kafka 서버와 Zookeeper를 기동해서 사용해보자. cmd 창은 Zookeeper, Kafka 서버에 하나씩 Producer, Consumer에 하나씩 총 4개를 켜놓아야 한다. 모든 명령은 Kafka 설치 경로에서 이루어진다.
windows는 bin>windows 에 Kafka 실행 명령어가 저장되어 있음에 주의한다.
# Version 확인
bin\windows\kafka-topics.bat --version
# Zookeeper 실행
bin\windows\zookeeper-server-start.bat config\zookeeper.properties
# Kafka 실행
bin\windows\kafka-server-start.bat config\server.properties
# Topic 생성
bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --topic stock-update
# Topic 생성 - partitions, replication-factor
bin\windows\kafka-topics.bat --create --bootstrap-server localhost:9092 --topic stock-update --partitions 1 --replication-factor 1
# Topic 확인
bin\windows\kafka-topics.bat --describe --bootstrap-server localhost:9092 --topic stock-update
# Topic 목록
bin\windows\kafka-topics.bat --list --bootstrap-server localhost:9092
# Topic 삭제
bin\windows\kafka-topics.bat --delete --bootstrap-server localhost:9092 --topic stock-update
# Producer
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic stock-update
# Producer - Key, Value
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic stock-update --property "parse.key=true" --property "key.separator=:" --property "print.key=ture"
# Producer - Message
ABCDE
# Producer - Key, Value Message
key:{"val1":"A","val2":"B","val3":3}
# Consumer
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic stock-update --from-beginning
# Consumer Group 확인
bin\windows\kafka-consumer-groups.bat --list --bootstrap-server localhost:9092
# Consumer Group Topic 확인
bin\windows\kafka-consumer-groups.bat --describe --bootstrap-server localhost:9092 --group stock-update-group1. Zookeeper 구동
기본 port: 2181
bin\windows\zookeeper-server-start.bat config\zookeeper.properties[오류 해결]
"입력 명령어 줄이 너무 깁니다." 오류가 떴다.
최대한 root에 가깝게 Kafka 위치를 바꿨더니 해결됐다.
2. Kafka Server 구동
기본 port: 9092
bin\windows\kafka-server-start.bat config\server.properties3. Topic 생성
bin\windows\kafka-topics.bat --bootstrap-server localhost:9092 --create --topic quickstart-events --partitions 1이름은 quickstart-events 로 설정함.
4. Producer 실행
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic quickstart-events5. Consumer 실행
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic quickstart-events --from-beginning--> 한글이라 다 깨져서 나오는 듯 하지만 Producer에서 보낸 메시지가 Consumer로 잘 전달됨을 알 수 있다.
오타가 좀 열받게 나네
Producer가 Consumer에게 직접 메시지를 전달하는 것이 아니라, Topic에 등록한 Consumer에게만 메시지가 전달됨을 알 수 있다.
Kafka Connect
이전에는 코드 등을 이용해서 각 서비스들끼리 Client가 되어 Prod/Cust 구조로 메시지를 공유했다. 이제 Connect 를 통해 Source System에서부터 Data를 Import 해 Target System으로 Data를 Export 할 수 있다.
즉, 코드 없이 Configuration 만으로 데이터를 이동할 수 있다.
Standalone 혹은 Distribution 모드로 작동할 수 있다. 데이터는 RESTful API 를 통해 Stream 혹은 Batch 형태로 전송할 수 있고, 커스텀 Connector를 통해 다양한 Plugin 을 제공한다.
order-service 에 MySQL을 연동시켜 Connect 동작을 시켜볼 것이다.
order-service의 pom.xml에 MySQL 연동을 위한 의존성을 추가한다.
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>windows 환경의 경우 mysql.server start가 아닌 net start mysql을 해주어야 한다.
[오류 해결]
net start mysql을 입력하니
"서비스 이름이 잘못되었습니다.
NET HELPMSG 2185을(를) 입력하면 도움말을 더 볼 수 있습니다."
이런 오류가 떴다.
일단 관리자 권한으로 실행하고 mysqld -install을 입력해준다. 다시 net start mysql을 입력하면 아래와 같은 오류가 뜬다.
port 충돌 오류였다.
충돌하는 port 중지하고 실행하니 잘 된다.
https://humahumahuma.tistory.com/285
윈도우10 APM 설치시 'MySQL 서비스를 시작할 수 없습니다'
C:\WINDOWS\system32>net start mysql MySQL 서비스를 시작합니다... MySQL 서비스를 시작할 수 없습니다. 서비스가 오류를 보고하지 않았습니다. NET HELPMSG 3534을(를) 입력하면 도움말을 더 볼 수 있습니다. MySQL
humahumahuma.tistory.com
--> 근데 이 오류인지 모르고 data 폴더도 날리고 초기화 명령어도 때려서 후에 mysql을 사용할 때 오류가 터질까봐 조금 무섭다
[오류 해결]
mysql 비밀번호 까먹었다.
재설정으로 1234 로 바꿨다.
https://kukuta.tistory.com/248
[MySQL] root 패스워드 분실 시 리셋 방법
만일 여러분이 한번도 MySQL root 계정의 패스워드를 설정한적이 없다면 root로 접속 할 때 패스워드를 묻지 않습니다. 패스워드를 설정하지 않으면 매번 접속 할 때 마다 귀찮게 패스워드를 묻지도
kukuta.tistory.com
다시 돌아와서, mysql에 접속하고 mysql -uroot -p 를 입력하여 비밀번호까지 입력한 다음, mydb table을 생성한다.
discovery-service, apigateway-service, order-service를 차례대로 실행하고 h2-console을 확인한다.
다음과 같이 바꿔주고 user name엔 root, 비밀번호엔 아까 설정한 1234 를 입력한다.
mydb에 users table까지 생성 완료(그런데 저만 mydb에 파일 조낸 많나요?)
Kafka Connection
http://packages.confluent.io/archive/7.4/confluent-community-7.4.0.tar.gz
- 버전 정보: 7.4
--> 강사님처럼 curl -O http://packages.confluent.io/archive/7.4/confluent-community-7.4.0.tar.gz 명령어 쓰려고 하니까 permisson denied 뜬다. 그냥 직접 링크 이동해서 다운로드 했다.
tar xvf confluent-community-7.4.0.tar.gz
--> cmd에 해당 압축 해제 명령을 하니 tar: Error exit delayed from previous errors. 이런 오류가 떠서 해제가 안된건가 싶었는데 해당 폴더로 이동하니 압축 해제가 되어 있었다. 혹시 나중에 오류가 생길까봐 ignore 명령어도 안썼는데 아무튼 된거 같다.
[참고]
-tar.gz 압축풀기
tar -xvzf (압축파일명).tar.gz
--> 이 방법을 시도해 해제하려고 했는데, 혹시 계속 문제가 생긴다면 xvf말고 xvzf 사용해보길
Kafka connect를 실행해 보자. Zookeeper와 Kafka는 실행되고 있는 상태여야 한다.
bin\windows\connect-distributed.bat etc\kafka\connect-distributed.properties
[오류 해결]
강의에서 나온 오류가 아니라 아래와 같은 오류가 떴다.
Error: Could not find or load main class org.apache.kafka.connect.cli.ConnectDistributed
Caused by: java.lang.ClassNotFoundException: org.apache.kafka.connect.cli.ConnectDistributed
안녕하세요!! connector 실행시 오류가 생겨 질문 드립니다. - 인프런 | 질문 & 답변
D:\\KAFKA_HOME\\confluent-6.1.0>.\\bin\\windows\\connect-distributed.bat .\\etc\\kafka\\connect-distributed.properties[2021-06-10 15:43:28,943] WARN ...
www.inflearn.com
이 해결 방법을 사용하기 전에 또 다른 오류가 발생했다. 배치 파일이 열리지 않고 켜지자마자 down된다.
아마 win 10 os를 사용한다면 백신 문제일 가능성이 크다 한다.
McAfee LiveSafe 아마도 이 프로그램 때문인 것 같아 삭제하고 다시 하려 한다.
이더리움 채굴 배치파일이 바로 꺼진다면?
이더리움 피닉스 마이너 채굴 화면 꺼짐 오류 현상, 해결방법 이 블로그는 게재된 광고수익으로 운영됩니다. 정보가 도움이 되었다면 글쓴이에게 음료 한잔의 여유를 부탁드립니다. 가상화폐
dongdinolife.tistory.com
--> 결론은 보안 프로그램도 다 지워봤는데 배치 파일이 안열렸다.
인프런 방법대로 수정하려면 배치 파일 내부를 수정해야 한다.
혹시 하는 마음에 빈 메모장에 배치 파일을 드래그 했더니 수정이 가능하다!
저처럼 개고생하지 마시고 윈도우 사용자들은 오류가 발생했다면 빈 메모장에 .bat 드래그하고 수정하길
Kafka Connect 연결을 확인하고 Topic list를 다시 확인하면 이전에 없던 Topic들이 생성된 것을 볼 수 있다.
Connector 가 MySQL와 연동되어야 하기 때문에 JDBC Connector 가 추가로 필요하다. 다음 URL에 접속해 Download를 누른다.
https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
JDBC Connector (Source and Sink)
Confluent, founded by the original creators of Apache Kafka®, delivers a complete execution of Kafka for the Enterprise, to help you run your business in real-time.
www.confluent.io
--> 실제 우리가 필요로 하는 파일이다.
1. plugin.path 수정
confluent-7.4.0/etc/kafka/connect-distributed.properties 를 VS Code 로 열어서 plugin.path 값이 있을 것이다. 여기에 원래 값 대신 조금 전에 다운로드받은 파일의 경로를 지정할 것이다.
plugin.path=C:\confluentinc-kafka-connect-jdbc-10.7.4\lib2. mysql 라이브러리 복사
\.m2\repository\com\mysql\mysql-connector-j\8.0.33>
--> 이 경로로 이동해서 필요한 파일을 확인한다. 여기 있는 파일 중 jar 파일을 Connector 가 쓸 수 있도록 Connector의 영역에 복사해 줄 것이다.
copy mysql-connector-j-8.0.33.jar C:\confluent-7.4.0\share\java\kafka
Kafka Source Connect 사용
MySQL에서 변경이 일어나면 Kafka Cluster에게 전해주는 Source Connect를 기동하고 사용해보자.
다음 명령어로 Source Connect를 기동한다.
bin\windows\connect-distributed.bat etc\kafka\connect-distributed.properties
[오류 해결]
분명 plugin.path 에 jdbc 경로를 지정해 줬는데 인식을 못한다.
http://localhost:8083/connector-plugins--> 해당 경로로 사용할 수 있는 플러그인 정보를 확인해 보니 JDBC 관련 플러그인 목록이 확인이 안된다.
알고보니 windows는 경로 지정 시 \ 하나가 더 붙어야 한다고 한다. (개같은 윈도우)
plugin.path=\C:\\confluentinc-kafka-connect-jdbc-10.7.4\\lib그리고 내 mydb 안에 있는 users 데이터베이스에서 변경이 일어나면 알아차리는 Topic을 생성하자. RESTful API 로 할 수 있어서 Postman을 활용해 등록하면 된다.
{
"name": "my-source-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"connection.user": "root",
"connection.password": "1234",
"mode": "incrementing",
"incrementing.column.name": "id",
"table.whitelist": "mydb.users",
"topic.prefix": "my_topic_",
"tasks.max": "1"
}
}--> 여기서 Topic은 prefix 이름에 실제 이름를 더한 것이다. 이 경우 my_topic_users 가 된다.
--> topic.whitelist 에는 우리의 경우 테이블 이름을 써야 하는데, 그냥 user라고 쓰면 다른 데이터베이스의 테이블과 구분하지 못해 mydb.users와 같이 db.table 형식으로 써야 한다.
https://www.inflearn.com/questions/618181/source-connector-%EC%98%A4%EB%A5%98
Source Connector 오류 - 인프런 | 질문 & 답변
- 학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!- 먼저 유사한 질문이 있었는지 검색해보세요.- 서로 예의를 지키며 존중하는 문화를 만들어가요.- 잠깐! 인프런 서비스 운영 관련 문
www.inflearn.com
get 방식으로 호출하면 현재 등록된 connector 정보를 확인할 수 있다.
[오류 해결]
mydb.users로 해결된 줄 알았는데 아니었다.
kafka connect log를 보니 인증 오류 같았다.
알고보니 mysql 8.0 부터 RSA 보안을 사용하지 않으면 오류가 난다고 한다.
https://kogle.tistory.com/87#comment15369241
MySql : MySql 8.0이상 caching_sha2_password authentication plugin 문제해결
1. MySql 8.0은 SHA-256 hashing을 구현하는 두 가지 인증 플러그인을 지원한다. 1-1 sha256_password - 기본적인 SHA-256 인증을 구현한 플러그인 1-2 caching_sha2_password - sha256_password와 동일한데 성능 향샹을 위해
kogle.tistory.com
ALTER USER 'yourusername'@'localhost' IDENTIFIED WITH mysql_native_password BY 'youpassword';--> mysql 접속해서 해당 명령어 입력하고 다시 postman get 요청을 보내봤더니 성공했다.
변경이 있어야 Connector가 Topic을 자동으로 만들어주기 때문에 db에 다음과 같이 데이터를 삽입한다.
--> connector과 연결한 users table에 변동점이 생겼으므로 my_topic_users 라는 Topic이 생성된 것을 볼 수 있다.
Consumer을 생성해 테스트를 진행해 본다.
bin\windows\kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic my_topic_users --from-beginning데이터베이스 입력에 대한 JSON 파일이 나온다.
실제로 테이블의 정보들이 들어있어, 데이터를 전달 받은 쪽에서 똑같은 데이터를 데이터베이스에 넣을 수 있도록 되어 있다.
--> 테스트용으로 db에 데이터를 하나 더 생성하니 자동으로 Topic에 정보가 반영됨을 알 수 있다.
Json 형식의 위 값을 사용하게 되면 db에 직접 자료를 넣지 않더라도 Topic에 값을 전달하게 되면 그 값이 db에 반영된다.
이를 도와주는 것이 kafka sink connect 이다.
Kafka Sink Connect 사용
Sink Connect의 역할은 Topic에 전달된 데이터를 가져와서 사용하는 것이다.
따라서 Sink Connect와 연결될 Topic은 "topics" 에 지정하면 된다.
테스트를 위해선 Zookeeper, Kafka Server, Connector, Consumer가 띄워져 있는 상태여야 한다.
[오류 해결]
Kafka Sink Connect를 추가해야 하는데
"error_code": 400, "message": "Connector configuration is invalid and contains the following 4 error(s):\nQuery mode must be specified\nQuery mode must be specified\nQuery mode must be specified\nQuery mode must be specified\nYou can also find the above list of errors at the endpoint `/connector-plugins/{connectorType}/config/validate`" }
이런 오류가 떴다. 400 bad request인 걸 봐선 요청에 뭔가 누락되었거나 오타인 것 같은데 아무리 봐도 오타는 아니다.
알고보니 요청에 "mode" 가 누락된 것이었다. 강사님은 강의에서 "mode" 를 따로 지정하지 않는데 오류가 뜨는 이유를 잘 모르겠다.
Kafka Connect JDBC 소스 커넥터의 설정에는 `mode`라는 속성이 필요하며, 이는 데이터베이스로부터 데이터를 가져오는 방식을 나타냅니다. 당신이 제출한 구성에서 이 `mode`가 누락되었습니다. 이로 인해 위의 오류 메시지가 발생한 것입니다.
`mode` 설정은 다음과 같은 옵션들을 가질 수 있습니다:
1. `bulk`: 데이터베이스의 모든 행을 한 번에 가져옵니다.
2. `incrementing`: 단일 증가 컬럼을 기반으로 새로운 또는 수정된 행을 가져옵니다.
3. `timestamp`: 단일 타임스탬프 컬럼을 기반으로 새로운 또는 수정된 행을 가져옵니다.
4. `timestamp+incrementing`: 타임스탬프와 증가 컬럼을 결합하여 새로운 또는 수정된 행을 가져옵니다.
`incrementing`, `timestamp`, 또는 `timestamp+incrementing` 모드를 사용하는 경우, 해당 모드와 관련된 추가 설정이 필요할 수 있습니다. 예를 들면, `incrementing.column.name` 또는 `timestamp.column.name`과 같은 설정입니다.
따라서, 당신의 구성을 수정하려면 원하는 모드에 따라 `mode` 속성을 추가해야 합니다. 예를 들어, `incrementing` 모드를 사용하려는 경우 다음과 같이 구성을 수정할 수 있습니다:
```json
{
"name": "my-sink-connect",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url": "jdbc:mysql://localhost:3306/mydb",
"connection.user": "root",
"connection.password": "1234",
"mode": "incrementing",
"incrementing.column.name": "id",
"auto.create": "true",
"auto.evolve": "true",
"delete.enabled": "false",
"tasks.max": "1",
"topics": "my_topic_users"
}
}
```
여기서 `incrementing.column.name`는 증가하는 값을 가지는 데이터베이스의 컬럼 이름을 나타냅니다. 이 컬럼은 해당 테이블의 기본 키나 유니크한 값을 가져야 합니다.
--> 마땅히 구글링 결과가 안나와서 chatGPT한테 물어본 결과이다.
--> 아무튼 connect가 추가된 것을 확인했다.
정상적으로 추가가 되었다면 auto.create 설정으로 db에 Topic과 같은 이름으로 table이 추가되어야 한다.
그런데 table이 보이지 않는다.
당연하다. 내가 connector.class 를 잘못 지정해 줬기 때문이다. JdbcSourceConnector 로 지정해 놨는데 sink connect를 사용하려면 io.confluent.connect.jdbc.JdbcSinkConnector 를 사용해야 한다.
(계속 누락된 option이 있다길래 뭔가 했다. 당연히 누락된 거겠지)
--> auto.create로 Topic 이름과 같은 테이블이 자동 생성된 것을 알 수 있다.
--> users 에 데이터를 삽입해도 다른 테이블에 동기화 됨을 알 수 있다.
우리가 목표로 한 Sink Connect가 완벽히 이루어졌다.
마지막으로, 직전에 Consumer로 테스트 했을 때, JSON 형식으로 데이터를 잘 삽입할 수 있도록 가공되어 주어진다고 했다. 이걸 Producer 입장에서 그대로 Sink Connector 가 연결된 Topic에 보내본다.
Producer을 하나 생성해 보자.
bin\windows\kafka-console-producer.bat --bootstrap-server localhost:9092 --topic my_topic_users{"schema":{"type":"struct","fields":[{"type":"int32","optional":false,"field":"id"},{"type":"string","optional":true,"field":"user_id"},{"type":"string","optional":true,"field":"pwd"},{"type":"string","optional":true,"field":"name"},{"type":"int64","optional":true,"name":"org.apache.kafka.connect.data.Timestamp","version":1,"field":"created_at"}],"optional":false,"name":"users"},"payload":{"id":4,"user_id":"my_id","pwd":"my_pwd","name":"stopmsa","created_at":1693478873000}}
--> 이런 json format을 보내면 되는데 우리는 이 중에서 payload 부분을 임의로 수정해 보낼 것이다.
Producer가 보낸 값을 my_topic_users Topic을 사용하는 Consumer가 잘 받아왔음을 확인할 수 있다.
이 때 db의 users table을 확인해 보면 방금 Producer가 보낸 값이 반영이 되어 있지 않다.
users는 Topic으로부터 데이터를 가져오지 않고 자신의 데이터를 Topic에 밀어넣는 기능을 하기 때문인데 반면에 sink connect와 연결되어 있는 my_topic_users 는 데이터가 반영되어 있음을 알 수 있다.
이제 우리는 Kafka를 통해 기존에 만들었던 user, order 등의 service에 데이터 동기화 시키는 작업을 다음 섹션부터 진행해 볼 것이다.
+ 서버를 종료시킬 땐 ctrl+c 로 일괄 종료시키도록 하자.
할 수 있는 오류는 다 겪어본듯 슈발
'개발 > MSA' 카테고리의 다른 글
| 데이터 동기화를 위한 Apache Kafka의 활용 ② (0) | 2023.09.07 |
|---|---|
| 마이크로서비스간 통신 (0) | 2023.08.18 |
| 설정 정보의 암호화 처리 (0) | 2023.08.18 |
| Spring Cloud Bus (0) | 2023.08.11 |
| Configuration Service (0) | 2023.08.10 |