네트워크(2)
HTTP 버전별 구분
- 전체
- HTTP/0.9 (1991년)
- HTTP/1.0 (1996년)
- HTTP/1.1 (1997년): 가장 많이 사용 중
- RFC2068 (1997) -> RFC2616 (1999) -> RFC7230~7235 (2014)
- 현재 표준 스펙을 보려면 RFC7230 이후를 봐야 한다
- HTTP/2.0 (2015년): HTTP 1.1의 성능 개선 및 확장
- HTTP/3.0 (진행 중)
- 핵심
- HTTP 1.1이 모든 것의 기반이다
HTTP 0.9
- 특징
- HTTP 초기 버전을 구분하기 위해 부르는 버전 (1991년)
- 요청은 단일 라인으로 구성되며, 리소스에 대한 method는 GET만 존재
- 응답도 극도로 단순 (파일 내용 자체로만 구성)
- HTTP 헤더도 없고, HTML파일만 전송 가능했던 것이 특징
/* 요청 */
GET /mypage.html
/* 응답 */
<HTML>
A very simple HTML page
</HTML>
HTTP 1.0
- 특징
- HTTP 헤더(header) 개념이 도입되어 요청과 응답에 추가되며, 메타데이터를 주고 받고 프로토콜을 유연하고 확장 가능하도록 개선됨 (1996년)
- 버전 정보와 요청 method가 함께 전송되기 시작
- 상태 코드 라인도 응답의 시작부분에 추가되어 브라우저 요청의 성공과 실패를 파악 가능해짐
(상태 코드를 사용하여 브라우저는 캐시된 내용을 적절하게 관리할 수 있게 됨, ex: 304 Not Modified) - Content-Type 도입으로 HTML 이외의 문서 전송 기능이 가능해짐
- 한계
- 커넥션 하나당 요청 하나와 응답 하나만 처리 가능했음
-> 비효율적이며 서버 부하 문제 발생
-> HTTP 1.1에서 개선
- 커넥션 하나당 요청 하나와 응답 하나만 처리 가능했음
/* 요청 */
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
/* 응답 */
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
A page with an image <IMG SRC="/myimage.gif">
</HTML>
HTTP 1.1
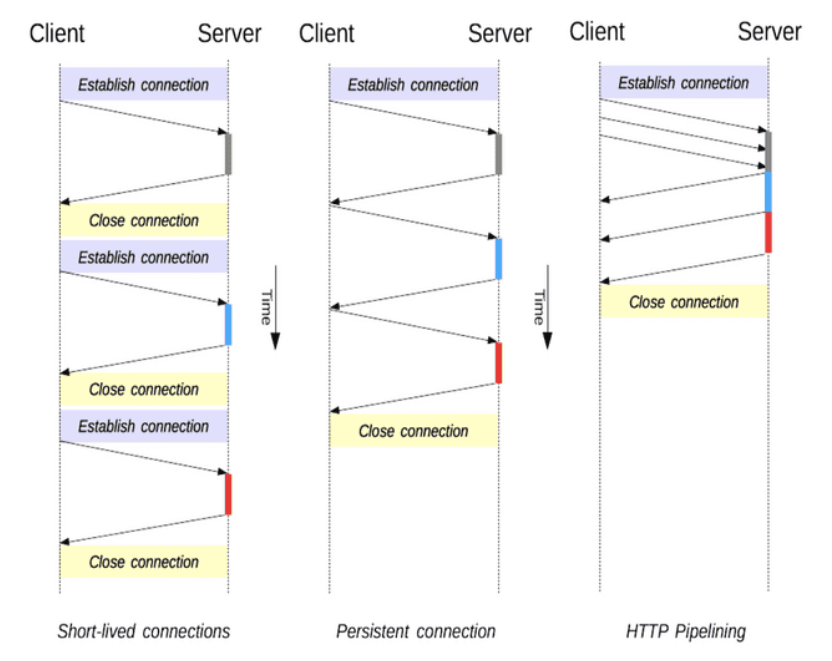
- 특징
- 1997년 등장
- Persistent Connection 추가
- 지정한 timemout 동안 커넥션을 닫지 않는 방법을 통해 커넥션의 사용성이 높아짐(Keep-Alive)
- Pipelining 추가
- 앞 요청의 응답을 기다리지 않고 순차적인 여러 요청을 연속적으로 보내고 그 순서에 맞춰 응답을 받는 방식이 등장
- 순차적으로 하나씩 요청 / 응답이 처리되는 기존 방식을 개선
- 하나의 커넥션에 여러개의 요청이 들어 있을 뿐, 동시에 여러개의 요청을 처리해 응답으로 보내주는 것은 아니다 (multiplexing 되지는 않음)
- 한계
- Head Of Line Blocking (HOLB)
: 서버가 항상 요청받은 순서대로 응답해야 하므로, 서버가 응답 작성 중간에 문제가 생기면 뒤 요청은 Blocking 되어버림 - Header의 중복
: 요청이나 응답에서 같은 헤더가 여러 번 반복되어 전송됨
- Head Of Line Blocking (HOLB)
/* 요청 */
GET /en-US/docs/Glossary/Simple_header HTTP/1.1
Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101 Firefox/50.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate, br
Referer: https://developer.mozilla.org/en-US/docs/Glossary/Simple_header
/* 응답 */
200 OK
Connection: Keep-Alive
Content-Encoding: gzip
Content-Type: text/html; charset=utf-8
Date: Wed, 20 Jul 2016 10:55:30 GMT
Etag: "547fa7e369ef56031dd3bff2ace9fc0832eb251a"
Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT
Server: Apache
Transfer-Encoding: chunked
Vary: Cookie, Accept-Encoding (content)
HTTP 2.0
- 설명
- 기존 HTTP 1.X 버전의 성능 향상에 초점을 맞춘 프로토콜 (2015년 등장)
- 표준의 대체가 아닌 확장 (표준 : HTTP 1.1)
- 특징
- HTTP 메시지 전송 방식의 전환
- Multiplexed Streams
- Stream Prioritization
- Server Push
- Header Compression
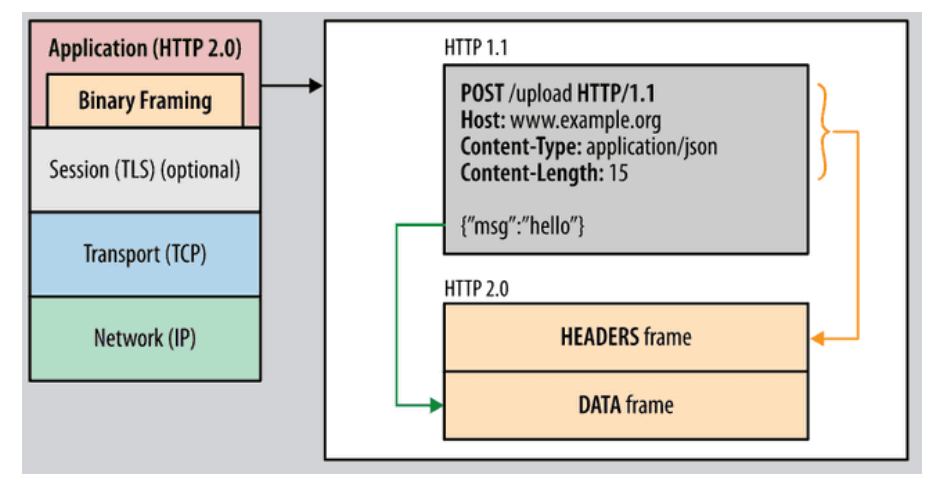
HTTP 메시지 전송 방식의 전환
- 기존 : 일반 텍스트 형식
- 개선
- Binary Framing 계층을 추가해서 보내는 메시지를 프레임(frame)이라는 단위로 분할하며 추가적으로 바이너리로 인코딩을 한다
(바이너리 형식 사용으로 파싱속도 및 전송 속도가 빠르고 오류 발생 가능성이 낮아짐)
- Binary Framing 계층을 추가해서 보내는 메시지를 프레임(frame)이라는 단위로 분할하며 추가적으로 바이너리로 인코딩을 한다

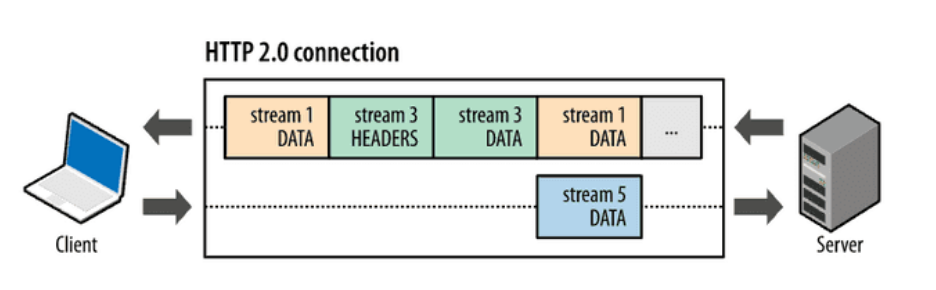
Multiplexed Streams
- 기존 : HTTP 1.1의 Pipelining 으로 하나의 커넥션에 여러 요청이 있지만, 결국 동시에 여러 요청을 처리해 응답으로 주지는 못하였음
- 개선
- TCP 연결을 메시지(message), 스트림(stream), 프레임(frame)이라는 단위로 세분화
메시지: 하나의 요청과 응답을 구성하는 단위
스트림: 요청과 응답이 양방향으로 오가는 논리적 연결 단위, TCP 연결에서 여러 개의 스트림이 동시에 존재할 수 있음, 각 스트림은 하나의 메시지를 전달하는데 사용
프레임: 메시지를 구성하는 최소 단위, 잘게 쪼개어 전송되기 때문에 수신 측에서 다시 조립하여 사용 - 메시지는 이진화된 텍스트인 frame으로 나뉘어 요청마다 구분되는 stream을 통해 전달된다. 즉, frame이 각 요청의 stream을 통해 전달되며, 하나의 커넥션 안에 여러 개의 stream을 가질 수 있게되어 다중화(multiplexing)가 가능해졌다.
-> 동시에 여러 요청을 처리하는 것이 가능해짐
-> stream을 통해 각 요청의 응답 순서가 의미 없어져 HOLB가 자연스럽게 해결됨
- TCP 연결을 메시지(message), 스트림(stream), 프레임(frame)이라는 단위로 세분화
Stream Prioritization
- 리소스간 우선순위를 설정하는 기능
- Stream에 우선순위를 부여해서 인터리빙되고 전달하는 것이 가능해짐
Server Push
- 단일 클라이언트 요청에 여러 응답을 보낼 수 있는 특징을 통해 Server에서 client에게 필요한 추가적인 리소스를 push해주는 기능
Header Compression
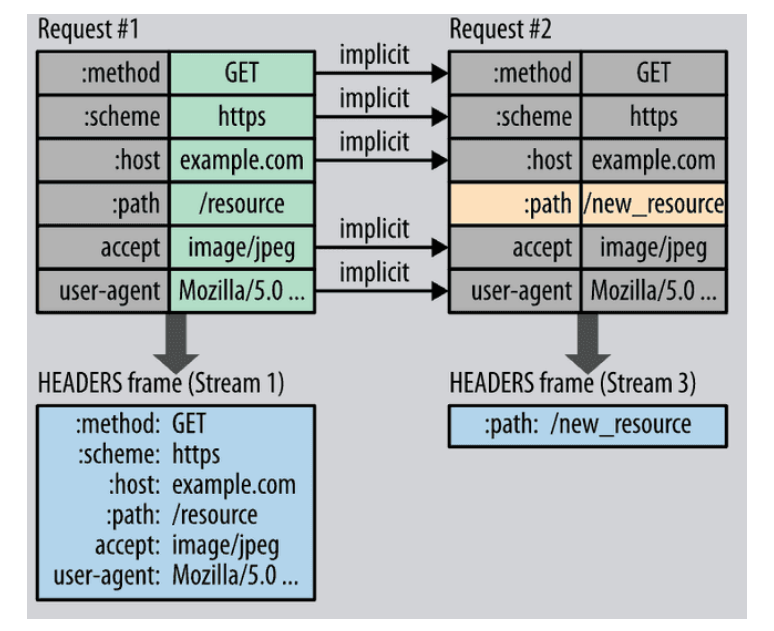
- 기존 : 연속된 요청의 경우 많은 중복된 헤더의 전송으로 오버헤드가 많이 발생했음
- 개선
- 요청과 응답의 헤더 메타데이처를 압축(HPACK)해서 오버헤드 최소화
- 전송되는 헤더 필드를 static dynamic table로 서버에서 유지
- 달라진 부분만 다시 전송하는 허프만 코딩(Huffman Coding) 기법을 사용(달라지지 않은 부분은 전송하지 않음)해서 데이터를 압축
[HTTP 2.0 한계]
- 각 요청마다 Stream으로 구분해서 병렬적으로 처리하지만, 결국 이에는 TCP 고유의 HOLB가 존재
- 왜냐하면, 서로 다른 Stream이 전송되고 있을 때 하나의 Stream에서 유실이 발생되거나 문제가 생기면 결국 다른 Stream도 문제가 해결될 때 까지 지연되는 현상이 발생되기 때문
- 즉, 이러한 TCP의 태생적인 HOLB를 해결하기 위해 QUIC / HTTP3.0이 등장
QUIC / HTTP 3.0
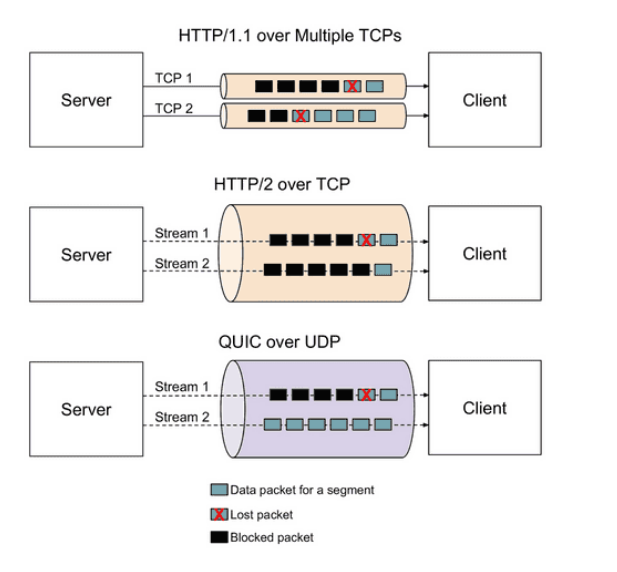
- QUIC
- Google에서 개발한 UDP 기반의 전송 프로토콜 (Quick UDP Internet Connections)
- Google에서 TCP의 구조적 문제로 성능 향상이 어렵다고 판단하여 UDP 기반을 선택
- QUIC는 신뢰성을 위해 패킷 재전송, 혼잡 제어, 흐름 제어 기능 등을 직접 구현. 즉, 신뢰성 기능이 제공되는 UDP 기반의 프로토콜
- QUIC는 TCP의 3-way handshake과정을 최적화 하는 것에 초점을 두고 개발됨(0-RTT)
- QUIC는 TCP의 Stream은 하나의 chain으로 연결되는 것과 다르게 각 Stream당 독립된 Stream chain을 구성하여 TCP HOL Blocking을 해결하였다
- HTTP 3.0
- QUIC를 기반으로 나온 새로운 HTTP 메이저 버전
HTTP vs HTTPS
HTTP(Hypertext Transfer Protocol)
서로 다른 시스템들 사이에서 통신을 주고받게 해주는 가장 기초적인 프로토콜이다. 예를 들어, 웹 서핑을 할 때 서버에서 내 브라우저로 데이터를 전송해 주는 용도로 사용된다. 인터넷 초기에 모든 웹 사이트에서 기본적으로 사용되었던 프로토콜이기도 하다.
HTTPS(Hypertext Transfer Protocol Secure)

HTTP 프로토콜의 문제점은 시스템 통신 시, 전송되는 정보가 암호화되지 않는다는 점이다. 즉 데이터가 쉽게 도난당할 수 있다는 것이다.
HTTPS 프로토콜은 SSL(보안 소켓 계층)을 사용함으로써 이 문제를 해결했다. SSL은 서버와 브라우저 사이에 안전하게 암호화된 연결을 할 수 있게 도와주고 서버와 브라우저가 민감한 정보를 주고받을 때 이것이 도난당하는 것을 막아준다.
💡 SSL vs TLS
TLS는 Transport Layer Security의 약자로 SSL의 업데이트 버전이다. 결과적으로 TLS는 SSL의 업데이트 버전이며 명칭만 다르다. 중요한 것은 SSL/TLS 프로토콜을 사용한 웹사이트 URL이 HTTP 대신 HTTPS를 사용한다는 것이다.
HTTPS 보안
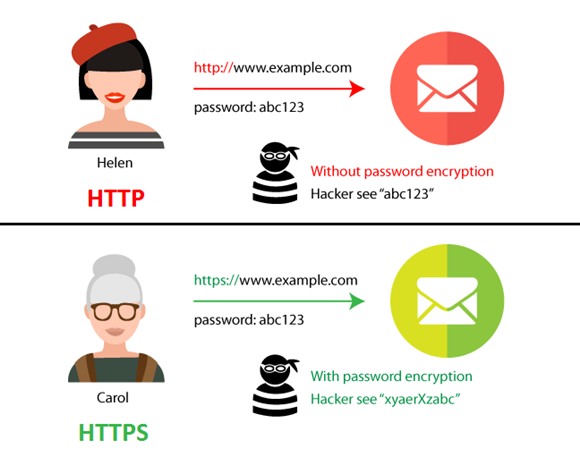
두 프로토콜 사이에 가장 큰 차이점은 바로 SSL/TLS 인증서이다. HTTPS는 쉽게 말해 HTTP+암호화이다. 이러한 보안 기능은 특히 신용 카드 정보나 비밀번호 등 사용자들의 민감한 정보들을 다루는 웹사이트라면 더욱 중요하다.
SSL/TLS 인증서는 사용자가 사이트에 제공하는 정보를 암호화하는데, 즉 데이터를 암호로 바꾼다고 생각하면 된다.
이렇게 전송된 데이터는 중간에서 누가 가로챈다고 하더라도 데이터가 암호화되어 있기 때문에 해독할 수 없다. 암호화 외에도 TLS는 웹사이트 소유자의 신원을 인증하기도 한다.
만약 웹사이트에 전자상거래 기능도 없고 방문자들의 민감한 정보를 다루지도 않는다면, HTTPS로 전환할 필요성이 크게 느껴지지 않을 수 있다. 하지만 HTTPS의 장점은 보안상 우위에만 있는 것이 아니다. HTTPS로 전환하게 되면 검색엔진 최적화(SEO)에 있어서도 큰 혜택을 볼 수 있다. 지난 2014년 구글에서는 HTTPS를 사용하는 웹 사이트에 대해서 검색 순위 결과에 약간의 가산점을 주겠다고 발표했고, 사용자들이 결국에는 가장 안전하다고 생각하는 사이트를 더 많이 방문하기 때문이기도 하다.
TCP 프로토콜의 3-way handshake와 4-way handshake
HTTP는 응용층 프로토콜로, 시스템들 사이에서 데이터를 주고받게 해주는 가장 기본적인 프로토콜이다. 그리고 앞서 HTTP 2.0의 한계로 TCP기반 통신으로 인한 HOLB와 이를 극복하기 위해 등장한 UDP기반의 HTTP 3.0을 언급했다.
따라서 TCP와 UDP를 간단히 설명하고 TCP 연결, 해제를 위한 3-way handshake와 4-way handshake를 살펴보겠다.
TCP/UDP
TCP/UDP는 전송층 프로토콜이다.
TCP 는 애플리케이션에게 신뢰적이고 연결지향성 서비스를 제공한다. 일반적으로 TCP는 IP와 함께 사용되며 IP는 배달을, TCP는 패킷의 추적 및 관리를 하게 된다.
TCP는 연결형 서비스로, 신뢰적인 전송을 보장하기에 3-way handshaking 과정을 통해 연결을 설정하고 4-way handshaking 과정을 통해 해제한다. 데이터의 흐름제어와 혼잡제어를 수행하지만 이러한 기능으로 인해 속도는 느리다. 신뢰성이 중요한 웹 페이지 로딩이나 파일 전송에 좋다.
UDP는 비연결형 프로토콜이다. 데이터를 서로 다른 경로로 독립적으로 처리한다.
UDP는 연결을 설정하고 해제하는 과정이 존재하지 않는다. 패킷에 순서를 부여하여 재조립하거나 흐름제어 및 혼잡제어를 수행하지 않아 속도가 빠르며 네트워크 부하가 적다는 장점이 있지만 데이터 전송의 신뢰성이 낮다. 연속성이 중요한 실시간 서비스(스트리밍)에 좋다.
💡 UDP와 TCP는 각각 별도의 포트 주소 공간을 관리하므로 같은 포트 번호를 사용해도 무방하다. 즉, 두 프로토콜에서 동일한 포트 번호를 할당해도 서로 다른 포트로 간주한다.
3-Way Handshake와 4-Way Handshake
3-way handshake는 TCP 접속, 4-way handshake는 TCP 접속 해제 과정이다.
포트(PORT) 상태 정보
- CLOSED: 포트가 닫힌 상태
- LISTEN: 포트가 열린 상태로 연결 요청 대기 중
- SYN_RCV: SYN 요청을 받고 상대방의 응답을 기다리는 중
- ESTABLISHED: 포트가 연결된 상태
플래그 정보
TCP 헤더에는 CONTROL BIT(플래그 비트, 6bit) 가 존재하며, 각 bit는 "URG-ACK-PSH-RST-SYN-FIN" 의 의미를 가지며 특정한 제어 신호나 TCP 패킷의 상태를 나타낸다. 만약 특정 위치의 bit가 1로 설정되어 있으면, 그 bit가 대표하는 특정 기능이나 상태가 활성화되었음을 의미한다.
- SYN(Synchronize Sequence Number) / 000010
- 연결 설정. Sequence Number을 랜덤으로 설정하여 세션을 연결하는 데 사용되며, 초기에 Sequence Number을 전송한다.
- ACK(Acknowledgement) / 010000
- 응답 확인. 패킷을 받았다는 것을 의미한다.
- Acknowledgement Number 필드가 유효한지 나타낸다.
- 양단 프로세스가 쉬지 않고 데이터를 전송한다고 가정하면 최초 연결 과정에서 전송되는 첫 번째 세그먼트를 제외한 모든 세그먼트의 ACK 비트는 1로 지정된다.
- FIN(Finish) / 000001
- 연결 해제. 세션 연결을 종료시킬 때 사용되며, 더 이상 전송할 데이터가 없음을 의미한다.
💡 TCP 연결과 데이터 전송 과정에서 각 단계별 포트 상태와 플래그 상태 예시
1. 클라이언트가 서버에게 SYN 패킷을 보낸다. (클라이언트에서 서버로의 초기 연결 요청)
플래그 상태: SYN = 1
클라이언트 포트 상태: SYN_SENT (클라이언트가 SYN을 보내고 ACK를 기다리는 상태)
2. 서버는 클라이언트로부터 SYN 패킷을 받고, 클라이언트에게 SYN과 ACK가 설정된 패킷(SYN-ACK)을 보내 응답한다. 이 때 서버는 SYN_RCV 상태가 된다.
플래그 상태: SYN = 1, ACK = 1
서버 포트 상태: SYN_RCV
3. 클라이언트는 SYN-ACK 패킷을 받고, 서버에게 ACK 패킷을 보내 연결을 확립한다.
플래그 상태: ACK = 1
클라이언트 포트 상태: ESTABLISHED
4. 서버는 클라이언트로부터 ACK 패킷을 수신하면 연결이 성공적으로 설정되었음을 인지하고, SYN_RCV 상태에서 ESTABLISHED로 전환한다.
플래그 상태: 플래그 변경 없이 포트 상태만 변경
서버 포트 상태: ESTABLISHED
5. 클라이언트가 시퀀스 번호 1부터 시작하는 데이터 패킷을 서버에 보낸다.
플래그 상태: PSH = 1, ACK = 1
6. 서버는 이 패킷을 받고, 다음에 기대하는 데이터의 시작 시퀀스 번호를 전송한다.(클라이언트로부터 100바이트를 받아 101이라고 가정하자) 따라서 Acknowledgement Number 필드는 101로 설정된다.
플래그 상태: ACK = 1
7. 클라이언트는 이 ACK 패킷을 받고 서버가 시퀀스 번호 101부터 시작하는 데이터를 기다리고 있음을 알게 된다.
3-Way Handshake
TCP 통신을 이용하여 데이터를 전송하기 위해 네트워크 연결을 설정하는 과정이다.
양쪽 모두 데이터를 전송할 준비가 되었다는 것을 보장하고, 실제로 데이터 전달이 시작하기 전에 한 쪽이 다른 쪽이 준비되었다는 것을 알 수 있도록 한다. 즉, TCP/IP 프로토콜을 이용해서 통신을 하는 응용 프로그램이 데이터를 전송하기 전에 먼저 정확한 전송을 보장하기 위해 상대방 컴퓨터와 사전에 세션을 수립하는 과정을 의미한다.
- 3-way handshake 기본 매커니즘
TCP 통신은 PAR(Positive Acknowledgement with Re-transmission) 을 통해 신뢰적인 통신을 제공한다.
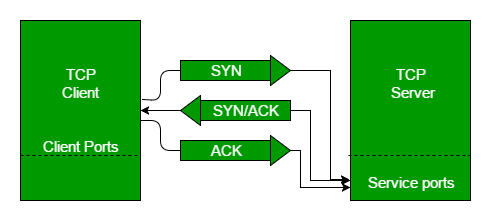
PAR을 사용하는 기기는 ACK를 받을 때까지 데이터 유닛을 재전송한다.
수신자가 데이터 유닛(세그먼트)이 손상된 것을 확인하면(Error Detection에 사용되는 전송층의 checksum을 활용), 해당 세그먼트를 없앤다. 그러면 송신자는 positive ack가 오지 않은 데이터 유닛을 다시 보내야 한다.
이 과정에서 클라이언트와 서버 사이에서 3개의 segment가 교환되는 것을 확인할 수 있다.
이것이 바로 3-way handshake의 기본 매커니즘이다.
- 작동 방식
클라이언트는 서버와 연결하기 위해 3-way handshake를 통해 연결 요청을 하게 된다.
(우리가 일반적으로 생각하는 클라이언트와 서버는 모두 서로 먼저 연결 요청을 할 수 있기 때문에, 연결 요청을 먼저 시도한 요청자를 클라이언트로, 연결 요청을 받은 수신자를 서버로 보면 된다.)

Step 1 (SYN)
클라이언트는 서버와 연결하기 위해 SYN을 보낸다. (seq: 324808530)
송신자가 최초로 데이터를 전송할 때 Sequence Number를 임의의 랜덤 숫자로 지정하고, SYN 플래그 비트를 1로 설정한 세그먼트를 전송한다.
PORT 상태
- Client: CLOSED에서 SYN_SENT 로 변함
- Server: LISTEN
Step 2 (SYN + ACK)
서버가 SYN(seq: 324808530) 를 받고, 클라이언트로부터 응답 확인 신호인 ACK와 SYN을 보냄 (seq: 288666267, ACK: 324808530+1)
접속 요청을 받은 서버가 요청을 수락했으며 접속 요청 프로세스인 클라이언트에게도 포트를 열어달라는 메시지를 전송(SYN-ACK signal bits set)
ACK Number 필드를 Sequence Number+1 로 지정하고 SYN과 ACK 플래그 비트를 1로 설정한 세그먼트 전송
PORT 상태
- Client: SYN_SENT
- Server: LISTEN에서 SYN_RCVD로 변함
Step 3 (ACK)
클라이언트는 서버의 응답인 ACK(324808530+1)과 SYN(288666267)을 받고, ACK(288666267+1)를 서버로 보냄
마지막으로 접속 요청 프로세스인 클라이언트가 수락 확인을 보내 연결을 맺음(ACK)
이 때, 전송할 데이터가 있으면 이 단계에서 데이터를 전송할 수 있다.
PORT 상태
- Client: SYN_SENT에서 ESTABLISED로 변함
- Server: SYN_RCVD에서 ESTABLISED로 변함
- full-duplex 통신의 구성
Step 1, 2에서는 Client->Server 방향에 대한 연결 파라미터(시퀀스 번호)를 설정하고 이를 승인한다.
Step 2, 3에서는 Server->Client 방향에 대한 연결 파라미터(시퀀스 번호)를 설정하고 이를 승인한다.
이를 통해 full-duplex 통신이 구축된다.
💡 TCP에서 Acknowledgement Number가 클라이언트의 시퀀스 번호에 1을 더한 값이 되는 상황은 주로 TCP 연결 초기화 단계에서 발생한다. 즉, SYN 패킷을 주고받을 때 그렇다. 그러나 데이터 전송 단계에서는 다를 수 있다.
4-Way Handshake
4-Way Handshake는 연결을 해제(Connection Termination)하는 과정이다. 여기서는 FIN 플래그를 이용한다.
- Termination의 종류
TCP는 대부분의 연결지향 프로토콜과 같은 두가지 연결 해제 방식이 있다.
1. Abrupt connection release(갑작스런 연결 해제)
갑자기 한 TCP 엔티티가 연결을 갑자기 종료하는 경우나 한 사용자가 두 데이터 전송 방향을 모두 닫는 경우 등을 말한다.
2. Graceful connection release(정상적인 연결 해제)
정상적인 연결 해제에서는 커넥션이 양쪽 모두 닫을 때까지 연결되어 있다.
- 작동방식 (Abrupt)
한 TCP 엔티티가 연결을 갑자기 종류하고 FIN 패킷을 보내지 않고 RST(TCP reset)세그먼트가 전송되면 갑작스러운 연결 해제가 수행되는데 RST세그먼트는 다음과 같은 경우에 전송된다.
1. 존재하지 않는 TCP 연결에 대해 SYN 플래그가 설정되지 않은 세그먼트가 수신된 경우
2. 열린 커넥션(이미 수립된 TCP 연결)에서 TCP 헤더 정보가 손상되었거나 예상치 못한 방식으로 변경된 패킷이 수신된 경우
3. 일부 구현에서 기존 TCP 연결을 종료해야 하는 경우
이 외에도 연결을 지원하는 리소스가 부족할 때, 원격 호스트에 연결할 수 없고 응답이 중지되었을 때 등이 있다.
- 작동방식 (Graceful)
연결 종료 요청 역시, 일반적으로 우리가 생각하는 Client와 Server는 모두 서로 연결 요청을 할 수 있기 때문에 연결 요청을 먼저 시도한 쪽을 Client, 연결 요청을 받은 쪽을 Server라고 생각하면 된다.
Half-Close 기법
아래 그림에서 처음 보내는 종료 요청인 FIN 패킷에 실질적으로 ACK가 포함되어 있는 것을 알 수 있는데, 이는 Half-Close 기법을 사용하기 때문이다.
즉, 연결을 종료하려고 할 때 완전히 종료하지 않고 한 쪽 방향의 데이터만 종료된다. 연결을 초기화한 쪽은 더이상 데이터를 보낼 수 없지만 반대편에서는 여전히 데이터를 보낼 수 있다.
Half-Close 기법을 사용하면 종료 요청자가 처음 보내는 FIN 패킷에 승인 번호(acknowledge number)를 함께 담아서 보내게 되는데, 이 때 승인 번호의 의미는 "일단 난 연결은 종료하는데 이 승인 번호까지 처리했으니까 더 보낼 거 있으면 보내" 가 된다.
이후 수신자가 남은 데이터를 모두 보내고 나면 다시 요청자에게 FIN패킷을 보냄으로써 모든 데이터가 처리되었다는 신호 FIN을 보낸다. 그럼 요청자는 ACK로 응답하면서 연결이 완전히 종료된다.

STEP 1 (Client -> Server : FIN(+ACK))
서버와 클라이언트가 연결된 상태에서 클라이언트가 close()를 호출하여 접속을 끊으려 한다.
이 때, 클라이언트는 서버에게 연결을 종료한다는 FIN을 보낸다. (FIN 패킷에는 실질적으로 ACK도 포함되어 있다.)
STEP 2 (Server -> Client : ACK)
서버는 FIN을 받고, 확인했다는 ACK를 클라이언트에게 보내고 자신의 통신이 끝날때까지 기다린다.
서버는 ACK Number 필드를 (Sequence Number + 1)로 지정하고 ACK 플래그 비트를 1로 설정한 세그먼트를 전송한다.
서버는 클라이언트에게 응답을 보내고 CLOSE_WAIT 상태에 들어간다.
이 상태는 서버가 클라이언트로부터 연결 종료 요청(FIN 패킷)을 받아들였으나 아직 데이터를 전송할 수 있는 것을 말한다. 그리고 아직 남은 데이터가 있다면 마저 전송을 마친 후에 close()를 호출한다.
클라이언트는 서버로부터 ACK를 받은 후에 서버가 남은 데이터 처리를 끝내고 FIN 패킷을 보낼 때까지 기다리게 된다. (FIN_WAIT 상태)
STEP 3 (Server -> Client : FIN)
데이터를 모두 보냈다면, 서버는 연결 종료에 합의한다는 의미로 FIN 패킷을 클라이언트로 보낸 후에, 승인 번호를 보내줄 때까지 기다린다.
STEP 4 (Client -> Server : ACK)
클라이언트는 FIN을 받고, 확인했다는 ACK를 서버에게 보낸다.
아직 서버로부터 받지 못한 데이터가 있을 수 있으므로 TIME_WAIT 을 통해 기다린다. (실질적인 종료과정 CLOSED에 들어가게 된다.)
이 때 TIME_WAIT 상태는 의도치 않은 에러로 인해 연결이 데드락으로 빠지는 것을 방지한다. 만약 에러로 인해 종료가 지연되다가 타임이 초과되면 CLOSED로 들어간다.
서버는 ACK를 받은 이후 소켓을 닫는다. (CLOSED)
TIME_WAIT 시간이 끝나면 클라이언트도 소켓을 닫는다. (CLOSED)

❓ TCP 연결 설정 과정(3단계)과 연결 종료 과정(4단계)이 차이나는 이유
Client가 데이터 전송을 마쳤더라도 Server는 아직 보낼 데이터가 남아있을 수 있기 때문에 일단 FIN에 대한 ACK만 보내고, 데이터를 모두 전송한 후에 자신도 FIN을 보내기 때문이다.
❓ Server에서 FIN 플래그를 전송하기 전에 전송한 패킷이 Routing 지연이나 패킷 유실로 인한 재전송 등으로 인해 FIN 패킷보다 늦게 도착하는 상황이 발생한다면
이러한 현상에 대비해 Client는 Server로부터 FIN 플래그를 수신하더라도 일정기간(Default: 240sec)동안 세션을 남겨 놓고 잉여 패킷을 기다리는 과정을 거친다. (TIME_WAIT)
❓ 초기 Sequence Number(ISN)를 0부터 시작하지 않고 난수를 생성하는 이유
TCP 연결은 서버와 클라이언트의 포트와 IP주소, 그리고 시퀀스 번호를 포함하여 고유하게 식별하게 된다. 난수로 ISN을 설정하면 같은 포트와 IP주소를 사용하더라도 연결을 구분할 수 있다. 순차적인 수가 사용된다면 이전 연결로부터 오는 패킷으로 인식할 수도 있다. 그 외에도 보안 강화, 연결 중복 방지 등의 이유가 있다.
HTTP Request/Response 메시지 구조
지금까지 전송 계층에서 TCP 연결을 설정하고 해제할 때 일어나는 과정을 알아보았다. 다음은 응용 계층에서 발생하는 HTTP 요청과 응답을 알아보겠다. HTTP는 기본적으로 request(요청)/response(응답) 구조이다. 클라이언트가 HTTP request를 서버에 보내면 서버는 HTTP response를 보낸다. 클라이언트와 서버의 모든 통신이 요청과 응답으로 이루어진다.
Request Message
HTTP Request Message는 공백(blank line)을 제외하고 3가지 부분으로 나뉜다. 각각 Start Line, Headers, Body이다.
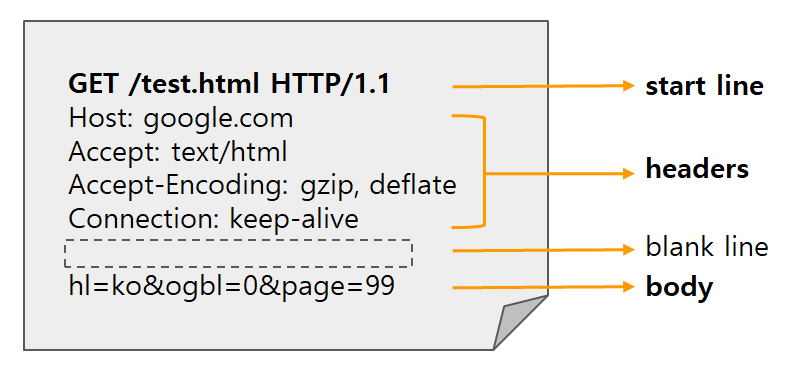
1) Start Line
Start Line에는 HTTP 메소드, Request target, HTTP version이 있다.
- HTTP method는 요청의 의도를 담고 있는 GET, POST, PUT, DELETE 등이 있다. GET은 존재하는 자원에 대한 요청, POST는 새로운 자원을 생성, PUT은 존재하는 자원에 대한 변경, DELETE는 존재하는 자원에 대한 삭제의 기능을 가지고 있다.
- Request target은 HTTP Request가 전송되는 목표 주소이다.
- HTTP version은 버전에 따라 Request 메시지 구조나 데이터가 다를 수 있어서 명시한다.
✨ PUT, PATCH 차이
PUT: 리소스의 모든 것을 업데이트한다.
PATCH: 리소스의 일부를 업데이트 한다.
2) Headers
해당 request에 대한 추가 정보를 담고 있는 부분이다. 예를 들어, request 메시지 body의 총 길이(Content-Length) 등이 있다. Key:Value 형태로 구성되어 있으며 크케 3가지로 나뉜다.(general headers, request headers, entity headers)
각각 요청과 응답 메시지 모두에 공통적으로 사용되는 헤더(Cache-Control, Date 등), 요청을 구체적으로 지정하는 헤더(Host, User-Agent, Accept 등), HTTP 메시지 본문(Content-Type, Content-Length 등)을 설명하는 헤더이다.
다음은 Request Header에서 주로 사용하는 정보이다.
- Host: 요청하려는 서버 호스트 이름과 포트번호
- User-agent: 클라이언트 프로그램 정보. 이 정보를 통해 서버는 클라이언트 프로그램(브라우저)에 최적화된 데이터를 보내줄 수 있다.
- Referer: 바로 직전에 머물렀던 웹 링크 주소
- Accept: 클라이언트가 처리 가능한 미디어 타입 종류 나열
- If-Modified-Since: 지정된 날짜 이후에 변경된 리소스만 요청한다.
- Authorization: 클라이언트 인증 정보를 서버에 제공한다.
- Origin: 주로 CORS( Cross-Origin Resoure Sharing) 처리에 사용되며 요청이 어느 주소에서 시작되었는지 나타낸다. 이 값으로 요청을 보낸 주소와 받는 주소가 다르면 CORS에러가 발생한다.
- Cookie: 클라이언트가 서버에 쿠키를 전달, 쿠키 값이 key-value로 표현된다.
3) Body
HTTP Request가 전송하는 데이터를 담고 있는 부분이다. 전송하는 데이터가 없다면 Body 부분은 비어있다. 보통 POST 요청일 경우, HTML form 데이터가 포함되어 있다.(Content-Type 헤더를 설정해 JSON 형식으로도 요청 가능)
Response Message
HTTP Response Message는 Request와 동일하게 공백(blank line)을 제외하고 3가지 부분으로 나뉜다. 각각 Status Line, Headers, Body 이다.

1) Status Line
HTTP Response의 상태를 간략하게 나타내는 부분으로 HTTP version, Status Code, Status Text로 구성되어 있다.
💡 Status Code 종류
- 1xx(정보): 처리 중인 상태, 서버가 클라이언트 요청을 받았으나 클라이언트가 요청을 계속 진행해야 한다는 것을 알린다.
- 2xx(성공): 요청이 성공적으로 처리된 상태
200 OK 일반적인 성공 상태
201 Created 클라이언트 요청으로 새로운 리소스가 생성된 상태
- 3xx(리다이렉션): 요청 완료를 위해 추가 작업 조치가 필요한 상태
- 4xx(클라이언트 오류): 요청의 문법이 잘못되었거나 요청을 처리할 수 없는 상태
- 5xx(서버 오류): 서버가 명백히 유효한 요청에 대한 충족을 실패한 상태
2) Header
- Location: 301 Moved Permanently와 302 Found 상태 코드와 같이, 리다이렉션을 나타내는 상태 코드와 함께 사용된다. 클라이언트가 요청을 다시 보내야 할 새로운 URL을 알려준다.
- Server: 웹 서버의 종류
- Age: 캐시된 응답이 얼마나 오래되었는지를 초 단위로 나타낸다. 즉, 응답이 처음 생성된 후부터 얼마나 시간이 지났는지를 나타낸다.
- Referrer-policy: 현재 페이지에서 다른 페이지로 네비게이션을 할 때 서버가 referrer 정보를 어떻게 전송해야 하는지 지정하는 값 ex) origin(도메인 정보만 전송), no-referrer(referrer 정보를 전송하지 않음), unsafe-url
- WWW-Authenticate: 사용자 인증이 필요한 자원을 요구할 시, 서버가 제공하는 인증 방식
- Proxy-Authenticate: 클라이언트가 프록시 서버로 자원에 접근할 때, 유저 인증을 위한 값
3) Body
HTTP Request 메시지의 Body와 동일하다. 마찬가지로 전송하는 데이터가 없으면 비어있다.
공통 Header
- Date: 현재 시간
- Cache-Control: 캐시 제어
- no-store: 캐시를 저장하지 않겠다.
- no-cache: 캐시된 데이터를 사용하기 전에 반드시 서버에게 검증을 요청한다.
- must-revalidate: 만료된 캐시는 반드시 서버에게 캐시 유효성을 검증받아야 한다.
- public: 공유 캐시(예: 프록시 서버)에 저장할 수 있다. 즉, 다수 사용자에게 캐시된 데이터가 제공될 수 있다.
- private: 브라우저와 같은 클라이언트 측 캐시에만 저장되어야 한다.
- max-age: 캐시의 최대 수명을 초 단위로 명시한다.
- Transfer-Encoding: 데이터가 네트워크를 통해 전송될 때 사용되는 인코딩 방식을 나타낸다.
- Content-Encoding:메시지 본문의 데이터 자체가 어떻게 압축 또는 인코딩되었는지 나타낸다.
- Conent-type: Body의 미디어 타입 ex) application/json, text/html
- Content-Length: Body의 길이
- Content-language: Body를 이해하는 데 가장 적절한 언어 ex) ko
- Connection: 클라이언트와 서버의 연결 방식 설정. 예를 들어 'keep-alive' 는 연결을 유지하겠다는 것을 의미한다.
HTTP Method
Request Message의 Start Line을 보면 Method가 존재하는 것을 알 수 있다. 여기서 HTTP 메서드란 클라이언트와 서버 사이에 이루어지는 요청(Request)과 응답(Response) 데이터를 전송하는 방식을 말한다. 쉽게 말해 서버가 수행해야 할 동작을 지정하는 요청을 보내는 방법이다.
HTTP 메서드 종류는 총 9가지가 있다. 이 중 주로 쓰이는 메소드는 5가지로 보면 된다.
- 주요 메서드
- GET: 리소스 조회
- POST: 요청 데이터 처리, 주로 등록에 사용
- PUT: 리소스 대체(덮어쓰기), 해당 리소스가 없으면 생성
- PATCH: 리소스 부분 변경 (PUT이 전체 변경, PATCH는 일부 변경)
- DELETE: 리소스 삭제
- 기타 메서드
- HEAD: GET과 동일하지만 메시지 부분(body 부분)을 제외하고, 상태 줄과 헤더만 반환
- OPTIONS: 대상 리소스에 대한 통신 가능 옵션(메소드)을 설명(주로 CORS에서 사용)
- CONNECT: 대상 자원으로 식별되는 서버에 대한 터널을 설정
- TRACE: 대상 리소스에 대한 경로를 따라 메시지 루프백 테스트를 수행
GET
리소스 조회 메서드(Read)
데이터를 요청하는 방식 중 주로 GET방식으로 데이터를 요청할 때 쓰이는 가장 단순한 데이터 전달 방법으로는 쿼리스트링(URL 뒤에 입력 데이터를 함께 제공하는 가장 단순한 데이터 전달 방법)이 있다.
예: GET /members/100?username=inpa&height=200
쿼리스트링 외에 메시지 바디를 사용해서 데이터를 전달할 수 있지만 금지가 되었던게 일반적이기 때문에 body를 담아 GET을 보내면 지원하지 않는 곳이 많아서 권장하지 않는다.
조회 시 POST도 사용할 수 있지만 GET 메서드는 캐싱이 가능하기 때문에 GET 요청이 더 유용하다.
POST
전달한 데이터 처리/생성 요청 메서드(Create)
메시지 바디(body)를 통해 서버로 요청 데이터를 전달하면 서버는 요청 데이터를 처리하여 업데이트한다.
전달된 데이터는 주로 신규 리소스 등록, 프로세스 처리에 사용된다.
만일 데이터를 GET하는데 있어, 메시지 바디로 데이터를 넘겨야 하는 경우 POST를 사용할 수 있다.
💡 Content-Type 헤더 종류
Content-Type: application/x-www-form-urlencoded
- 간단한 텍스트 데이터 전송 시 사용
- Form 내용을 HTTP 메시지 바디를 통해 전송(key1=value1&key2=value2... 의 쿼리 파라미터 형식)
- 전송 데이터를 url encoding 처리
예) abc김 => abc%EA%B9%80
Content-Type: multipart/form-data
- 파일 업로드 같은 바이너리 데이터 전송 시 사용
- 다른 종류의 여러 파일과 Form 내용을 함께 전송할 수 있다. 그래서 이름이 multipart이다.
Content-Type: application/json
- TEXT, XML, JSON 데이터 전송 시 사용(구조화된 데이터 형태로 전송)
PUT
리소스를 대체(수정)하는 메서드(Update)
만일 요청 메세지에 적힌 리소스가 있으면 덮어쓰고 없으면 새로 생성한다.
데이터를 대체해야 하니, 클라이언트가 리소스의 구체적인 전체 경로를 보내줘야 한다.
예: PUT /members/100 (100번째 멤버 수정)
PUT 요청에 일부 리소스만 변경하길 원할 경우에도 기존 데이터가 완전히 대체되기 때문에 데이터가 일부 삭제될 수 있다. 따라서 이 경우 PATCH 메소드를 이용해야 한다.
PATCH
리소스 일부 부분을 변경하는 메서드(Update)
만일 PATCH를 지원하지 않는 서버에선 대신에 POST를 사용할 수 있다.
DELETE
리소스 제거 메서드(Delete)
상태코드는 대부분 200을 사용하고 상황에 따라 204(서버가 요청을 성공적으로 처리했지만 콘텐츠를 제공하지 않는다.)를 사용한다.
❓ 204 상태코드가 가지는 의미는 클라이언트 요청은 정상적이지만 콘텐츠를 제공하지 않는다는 것이다.
즉, 200으로 응답하고 Response body에 null, false 등으로 응답하는 것과는 다르다.
204의 경우 HTTP Response body가 아예 존재하지 않는다.
삭제 요청으로 자원을 삭제하여 더 이상 존재하지 않고 그 자원을 참조하는 모든 자원도 삭제되어 더이상 HTTP body를 응답하는 것이 무의미해졌을 경우 사용한다.
HTTP 정책 - CORS
웹 개발을 하다보면 CORS 에러를 마주친 적이 있을 것이다. CORS는 Cross-origin-resource-sharing의 약자이다. 이 현상이 일어나는 이유는 웹 브라우저가 HTTP 요청에 대해 어떤 요청을 하느냐에 따라 각기 다른 특징을 가지고 있기 때문이다.
<img>, <video>, <script>, <link> 태그 등은 기본적으로 Cross-Origin 정책을 지원한다. 따라서 다른 사이트의 리소스에 접근할 수 있다.
그러나 XMLHttpRequest, Fetch API 스크립트는 기본적으로 Same-Origin 정책을 따른다. 예를 들어 다른 도메인의 소스에 대해 자바스크립트 ajax 요청 API 호출은 불가능하다. 자바스크립트에서의 요청은 기본적으로 서로 다른 도메인에 대한 요청을 보안상 제한한다.
그렇다면 Same Origin정책과 Cross Origin정책이란 무엇이길래 웹 브라우저가 외부 리소스를 가려 받는 것일까?
우리는 이 Same Origin/Cross Origin 정책의 위반하는 행동을 하게되어 CORS에러가 나타나는 것이다.
하지만 웹 개발을 하다보면 다른 도메인 서버에 있는 자원을 가져다 쓰거나 제공해 줄 일이 생길 것이다. 따라서 지금부터 이 CORS에러에 대해 알아보자.
CORS란?
CORS를 직역하면 교차 출처 리소스 공유 정책이라고 해석할 수 있는데, 여기서 교차 출처란 (엇갈린)다른 출처를 의미하는 것으로 보면 된다. 이처럼 교차 출처 리소스 공유는 다른 출처의 리소스 공유에 대한 허용/비허용 정책이다.
Warning !
Access to fetch at ‘https://myhompage.com’ from origin ‘http://localhost:3000’ has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource. If an opaque response serves your needs, set the request’s mode to ‘no-cors’ to fetch the resource with CORS disabled.
'https://myhomepage.com'에서'https://localhost:3000' 출처로 가져올 수 있는 액세스가 CORS 정책에 의해 차단되었습니다. 요청된 리소스에 'Access-Control-Allow-Origin' 헤더가 없습니다. 불투명한 응답이 필요에 적합한 경우, 요청 모드를 'no-cors'로 설정하여 CORS가 비활성화된 리소스를 가져오십시오.
여기서 언급한 출처(Origin)이란 다음과 같다.
우리는 어떤 사이트를 접속할 때 인터넷 주소창에 URL을 입력해 접근하게 된다. 그리고 이 URL은 여러개의 구성 요소로 이루어져 있다.

CORS를 이해하는 데 있어서 모든 URL 구성요소를 알아야하는 것은 아니고, 3가지만 기억하면 된다.
Origin: Protocol + Domain(Host) + Port
즉, 출처(Origin)라는 것은 Protocol과 Domain(Host) 그리고 Port까지 모두 합친 URL을 의미한다고 보면 된다.
출처(Origin)에 대해 알아봤으니 이제 Same Origin과 Cross Origin에 대해 자세히 알아보자.
먼저 SOP(Same Origin Policy)정책은 말 그대로 동일한 출처에 대한 정책을 말한다. 그리고 이 SOP정책은 동일한 출처의 리소스 공유만 허용한다.
즉, 동일 출처(Same-Origin)서버에 있는 리소스는 자유로이 가져올 수 있지만, 다른 출처(Cross-Origin)서버에 있는 리소스는 상호작용이 불가능하다는 것이다.
❓ 동일 출처 정책이 필요한 이유
두 애플리케이션이 제약 없이 소통할 수 있는 환경은 위험할 수 있다.
해커가 CSRF(Cross-Site Request Forgery)나 XSS(Cross-Site Scripting) 등의 방법을 이용해서 본인이 심어놓은 코드가 우리가 접속한 애플리케이션에서 실행된다면 개인정보를 가로챌 수 있다.
두 출처의 다름 유무를 판단하는 기준은 아까 언급했듯이 URL 구성 요소 중 Protocol, Host, Port 이 3가지이다.
정리하자면 같은 프로토콜, 호스트, 포트를 사용했을 때 그 뒤의 다른 요소는 다르더라도 같은 출처로 인정된다.
반대로 프로토콜, 호스트, 포트 중 하나라도 다를 경우 브라우저는 정책 상 차단하게 된다.
이러한 출처 구분 로직은 서버에 구현된 스펙이 아닌 브라우저에 구현된 스펙이다.
서버는 리소스 요청에 의한 응답은 멀쩡히 해주었다. 하지만 브라우저가 이 응답을 분석해서 일 출처가 아니면 CORS에러를 내는 것이다. (사실 서버가 헤더 정보를 덜 줘서 그렇다.)
그래서 브라우저에는 에러가 뜨지만, 정작 서버 쪽에서는 정상적으로 응답을 했다고 하기 때문에 난항을 겪는 것이다. 즉, 응답 데이터는 멀쩡하지만 브라우저 단에서 받을 수 없도록 차단한 것이다.
💡 브라우저가 정책으로 차단한다는 것은 브라우저를 통하지 않고 서버 간 통신을 할 땐 정책이 적용되지 않는다는 뜻이다.
즉, 클라이언트 단 코드에서 API 요청을 하는게 아니라 서버 단 코드에서 다른 출처의 서버로 API요청을 하면 CORS에러로부터 자유로워진다. 그래서 이를 이용한 프록시(Proxy)서버라는 것이 있다.
*클라이언트와 서버 사이에서 대리해주는 서버가 프록시 서버이다.
CORS 기본 동작
CORS error는 사실 브라우저의 SOP정책에 따라 다른 출처의 리소스를 차단하면서 발생된 에러이며, CORS는 다른 출처의 리소스를 얻기 위한 해결 방안이었던 것이다. 요약하자면 SOP 정책을 위반해도 CORS 정책에 따르면 다른 출처의 리소스라도 허용한다는 뜻이다.
1. 클라이언트에서 HTTP 요청 헤더에 Origin을 담아 전달
예) Origin: http://localhost:3000
2. 서버는 응답헤더에 Acess-Control-Allow-Origin을 담아 클라이언트로 전달한다.
해당 헤더의 값은 '이 리소스에 접근하는 것이 허용된 출처 url' 이다.
예) Access-Control-Allow-Origin: http://localhost:3000
3. 클라이언트에서 Origin가 서버가 보내준 Access-Allow-Origin을 비교한다.
만약 다른 출처라면 응답을 사용하지 않는다. (CORS 에러)
결국 CORS에러 해결책은 서버의 허용이 필요하다. 서버에서 Access-Allow-Origin 헤더에 허용할 출처를 기재해서 클라이언트에게 응답하면 되는 것이다. 즉, CORS에러는 백엔드 개발자가 고쳐야 할 부분이다.
💡 클라이언트에서 미리 자바스크립트로 origin 헤더 값을 위조하는 것은 브라우저에 감지되어 차단되기 때문에 불가능하다.
CORS 해결 방법
1. 프록시 사이트 이용하기
프록시(Proxy)란 클라이언트와 서버 사이의 중계 대리점이라고 보면 된다.
즉, 프론트에서 직접 서버에 리소스를 요청했더니 서버에서 따로 설정을 안해줘서 CORS에러가 뜬다면 모든 출처를 허용한 서버 대리점(Proxy)을 통해 요청하면 되는 것이다.

다만 현재 무료 프록시 서버 대여 서비스들은 모두 악용 사례 때문에 api 요청 횟수 제한을 두어 실전 사용은 무리이다. 따라서 테스트용으로 사용하되, 실전에서는 직접 프록시 서버를 구축해야 한다.
2. 서버에서 Access-Control-Allow-Origin 헤더 세팅하기
직접 서버에서 HTTP 헤더 설정을 통해 출처를 허용하게 설정하는 가장 정석적인 해결책이다.
서버의 종류도 노드 서버, 스프링 서버, 아파치 서버 등 여러가지가 있으니 이에 대한 해결책도 각각 존재한다.
각 서버의 문법에 맞게 위의 HTTP 헤더를 추가해 주면 된다.
CORS에 연관된 HTTP헤더 값으로는 다음 종류가 있다. (모두 설정할 필요는 없다.)
// 헤더에 작성된 출처의 브라우저만 리소스에 접근할 수 있도록 허용함
// *이면 모든 곳에 공개되어 있음을 의미
Access-Origin-Allow-Origin: https://...
//리소스 접근을 허용하는 HTTP 메서드를 지정해 주는 헤더
Access-Control-Request-Methods: GET, POST, PUT, DELETE
// 요청을 허용하는 헤더
Access-Control-Allow-Headers : Origin,Accept,X-Requested-With,Content-Type,Access-Control-Request-Method,Access-Control-Request-Headers,Authorization
// 클라이언트에서 preflight 의 요청 결과를 저장할 기간을 지정
// 60초 동안 preflight 요청을 캐시하는 설정으로, 첫 요청 이후 60초 동안은 OPTIONS 메소드를 사용하는 예비 요청을 보내지 않는다.
Access-Control-Max-Age : 60
// 클라이언트 요청이 쿠키를 통해서 자격 증명을 해야 하는 경우에 true.
// 자바스크립트 요청에서 credentials가 include일 때 요청에 대한 응답을 할 수 있는지를 나타낸다.
Access-Control-Allow-Credentials : true
// 기본적으로 브라우저에게 노출이 되지 않지만, 브라우저 측에서 접근할 수 있게 허용해주는 헤더를 지정
Access-Control-Expose-Headers : Content-Length
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.CorsRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
@Configuration
public class WebConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**") // 모든 경로에 대해
.allowedOrigins("http://localhost:3000") // localhost:3000에서 오는 요청 허용
.allowedMethods("GET", "POST", "PUT", "DELETE", "PATCH", "OPTIONS") // 허용할 HTTP 메서드
.allowedHeaders("*") // 모든 헤더 허용
.allowCredentials(true) // 쿠키 및 인증 정보 포함 허용
.maxAge(3600); // pre-flight 요청의 캐시 시간 (초 단위)
}
}
💡 사실 브라우저는 요청을 보낼 때 먼저 예비 요청(pre-flight)을 보내 서버와 잘 통신되는지 확인한 후 본 요청을 보낸다. 이 예비요청의 HTTP 메소드는 OPTIONS이다.
예비 요청을 보내 보안을 강화하는 취지는 좋지만 실제 요청에 걸리게 되는 시간이 늘어나게 될 수 있다. 따라서 브라우저 캐시를 이용해 헤더에 캐시될 시간을 명시해 주면 이 pre-flight 요청을 캐싱 시켜 최적화시킬 수 있다.
자격 인증 정보(Credential)란 세션ID가 저장되어 있는 쿠키(Cookie)혹은 Authorization헤더에 설정하는 토큰 값 등을 일컫는다.
즉, 클라이언트에서 일반적인 JSON데이터 외에도 쿠키 같은 인증 정보를 포함해서 다른 출처의 서버로 전달할 때 CORS의 인증된 요청으로 동작된다는 말이다.
쿠키, 세션
쿠키와 세션은 HTTP 프로토콜의 특징이자 약점을 보완하기 위해서 사용한다. 여기서 언급한 HTTP 프로토콜의 특징은 두 가지이다. 먼저, HTTP 프로토콜이 Connectionless(비연결 지향)프로토콜이라는 것이다. 이는 클라이언트가 서버에 요청(Request)을 했을 때, 그 요청에 맞는 응답(Response)을 보낸 후 연결을 유지하지 않고 끊는 처리방식이기 때문이다.
따라서 서버는 상태 정보를 유지하지 않는데 이러한 특성은 HTTP를 Stateless(상태가 없는)프로토콜로 만든다.
서버가 연결 상태를 유지할 필요가 없기 때문에 많은 수의 클라이언트와 통신할 수 있고, 자원을 효율적으로 관리할 수 있다. 그러나 이로 인해 각 요청이 독립적이므로 이전 요청에 대한 정보를 유지하기 위해서는 쿠키나 세션 같은 메커니즘이 필요한 것이다.
HTTP/1.1부터는 커넥션을 계속 유지하고 요청(Request)에 재활용하는 기능이 추가되었다. HTTP Header에 keep-alive 옵션을 주어 커넥션을 재활용하게 한다. HTTP 1.1 버전에선 디폴트 옵션이다.
HTTP가 TCP 위에서 구현되었기 때문에(연결 지향) 연결 지향적이라고 할 수 있다는 논란이 있지만 아직까진 네트워크 관점에서 keep-alive는 옵션으로 두고 HTTP 자체의 비연결성과 상태 비저장 특성은 변하지 않는다.
❓ 정보가 유지되지 않는다면
정보가 유지되지 않으면, 매번 페이지를 이동할 때마다 로그인을 다시 하거나
상품을 선택했는데 구매 페이지에서 선택한 상품의 정보가 없거나 하는 등의 일이 발생할 수 있다.
따라서 Stateful을 위해 쿠키와 세션을 사용하는 것이다.
쿠키와 세션의 차이는 크게 상태 정보의 저장 위치이다.
쿠키는 '클라이언트(=로컬 PC)'에 저장되고, 세션은 '서버'에 저장된다.
쿠키(Cookie)
HTTP의 일종으로 사용자가 어떠한 웹사이트를 방문할 경우, 그 사이트가 사용하고 있는 서버에서 사용자 컴퓨터에 저장하는 작은 기록 정보 파일이다. HTTP에서 클라이언트 상태 정보를 클라이언트 PC에 저장했다가 필요 시 정보를 참조하거나 재사용할 수 있다.
특징
- 이름, 값, 만료일(저장기간), 경로 정보로 구성되어 있다.
- 클라이언트에 총 300개의 쿠키를 저장할 수 있다.
- 하나의 도메인 당 20개의 쿠키를 가질 수 있다.
- 하나의 쿠키는 4KB(=4096byte)까지 저장 가능하다.
쿠키 동작 순서
- 클라이언트가 페이지를 요청한다.(사용자가 웹페이지에 접근)
- 웹서버는 쿠키를 생성한다.
- 생성한 쿠키에 정보를 담아 HTTP 화면을 돌려줄 때, 같이 클라이언트에게 돌려준다.
- 넘겨받은 쿠키는 클라이언트가 로컬 PC에 저장해 두고 있다가 다시 서버에 요청할 때 요청과 함께 쿠키를 전송한다.
- 동일 사이트 재방문 시 클라이언트 PC에 해당 쿠키가 있는 경우 서버에 요청 페이지와 함께 쿠키를 전송한다.
예) 팝업창을 통해 "오늘 이 창을 다시 보지 않기" 체크
세션(Session)
일정 시간 동안 같은 사용자(브라우저)로부터 들어오는 일련의 요구를 하나의 상태로 보고, 그 상태를 유지시키는 기술이다. 여기서 일정 시간은 방문자가 웹 브라우저를 통해 웹 서버에 접속한 시점부터 웹 브라우저를 종료하여 연결을 끝내는 시점을 말한다. 즉, 방문자가 웹 서버에 접속해 있는 상태를 하나의 단위로 보고 그것을 세션이라고 한다.
특징
- 웹 서버에 웹 컨테이너 상태를 유지하기 위한 정보를 저장한다.
- 웹 서버에 저장되는 쿠키(=세션 쿠키)
- 브라우저를 닫거나, 서버에서 세션을 삭제했을 때만 삭제가 되므로 쿠키보다 비교적 보안이 좋다.
- 서버 용량이 허용하는 한에서 저장 데이터 제한이 없다.
- 각 클라이언트에 고유 Session ID를 부여한다. Session ID로 클라이언트를 구분해 각 요구에 맞는 서비스를 제공한다.
세션 동작 순서
- 클라이언트가 페이지에 요청한다.
- 서버는 접근한 클라이언트의 Request-Header 필드인 Cookie를 확인하여 클라이언트가 해당 session-id를 보냈는지 확인한다.
- session-id가 존재하지 않는다면 서버는 session-id를 생성해 클라이언트에게 넘겨준다.
- 클라이언트는 서버로부터 받은 session-id를 쿠키에 저장한다.
- 클라이언트는 서버에 요청 시 이 쿠키의 session-id 값을 같이 서버에 전달한다.
- 서버는 전달받은 session-id로 session에 있는 클라이언트 정보를 가지고 요청을 처리 후 응답한다.
예) 화면을 이동해도 로그인이 풀리지 않고 로그아웃하기 전까지 유지
쿠키와 세션의 차이
쿠키와 세션은 비슷한 역할을 하며, 동작 원리도 비슷하다. 그 이유는 세션도 결국 쿠키를 사용하기 때문이다.
큰 차이점은 사용자의 정보가 저장되는 위치이다. 쿠키는 서버의 자원을 전혀 사용하지 않으며 세션은 서버의 자원을 사용한다.
보안 면에서는 세션이 더 우수하다. 쿠키는 클라이언트 로컬 PC에 저장되기 때문에 변질되거나 request에서 스니핑당할 우려가 있어서 보안에 취약하지만 세션은 쿠키를 이용해서 session-id만 저장하고 그것으로 구분하여 서버에서 처리하기 때문에 비교적 보안성이 높다.
라이프 사이클은 쿠키도 만료기간이 있지만 파일로 저장되기 때문에 브라우저를 종료해도 정보가 유지될 수 있다. 또한 만료기간을 따로 지정해 쿠키를 삭제할 때까지 유지할 수도 있다. 세션도 만료기간을 정할 순 있지만, 브라우저가 종료되면 만료기간에 상관없이 삭제된다.
속도 면에서는 쿠키가 더 우수하다. 쿠키는 쿠키에 정보가 있기 때문에 서버에 요청 시 속도가 빠르고 세션은 정보가 서버에 있기 때문에 서버에서 처리가 요구되어 비교적 느린 속도를 낸다.
사실 가장 중요한 것은 라이프 사이클이다.
❓ 왜 세션과 쿠키를 모두 사용할까
세션이 쿠키에 비해 보안 면에서는 우수하나 세션은 서버에 저장되고 서버 자원을 사용하기에 한계가 있고 속도가 느려질 수 있다. 자원관리 차원에서 쿠키와 세션을 적절한 요소 및 기능에 병행 사용하면 서버 자원의 낭비를 방지하면서 웹사이트 속도를 높일 수 있다.
쿠키와 세션을 캐시(Cache)와 헷갈리면 안된다.
캐시는 웹페이지 요소를 저장하기 위한 임시 저장소이고, 쿠키/세션은 정보를 저장하기 위해 사용된다. 캐시는 웹페이지를 빠르게 렌더링할 수 있도록 도와준다. 이미지, 비디오, 오디오, css, js 파일 등 데이터나 값을 미리 복사해 놓는 리소스 파일들의 임시 저장소이다. 쿠키/세션은 사용자의 인증을 도와준다.
HTTP Method의 멱등성
HTTP Method의 멱등성(Idempotence)이란?
HTTP 메서드의 속성 중에 안전(Safe), 캐시(Cacheable)과 함께 멱등성(Idempotence)이 있다. RFC7231 스펙 문서를 보면 멱등성이란 여러번 동일한 요청을 보냈을 때, 서버에 미치는 의도된 영향이 동일한 경우라고 정의되어 있다. 즉 동일한 요청을 한 번 보내는 것과 여러 번 연속으로 보내는 것이 같은 효과를 지니고, 서버의 상태도 동일하게 남을 때이다.
- 멱등성을 가진 메서드: GET, HEAD, PUT, DELETE, OPTIONS 등
- 멱등성을 가지지 않는 메서드: POST, PATCH

멱등성이 필요한 이유
HTTP 멱등성이 필요한 이유는 요청의 재시도 때문이다. 만약 HTTP 요청이 멱등하다면, 요청이 실패한 경우 재시도 요청을 하면 된다. 하지만 만약 HTTP 요청의 멱등하지 않다면, 리소스가 이미 처리되었는데 중복 요청을 보냈을 때 문제가 발생한다. 예를 들어 이미 결제(POST)된 요청인데, 중간에 연결이 끊겨서 다시 결제 요청을 보내서 문제를 일으킬 수 있는 것이다. 그래서 클라이언트 측에서 무지성 재시도 요청을 보내면 안되고, 멱등성을 고려하여 재시도 요청을 해야 한다. 물론 서버에서도 클라이언트 요청을 제어해야 한다.
HTTP 메소드의 멱등 여부
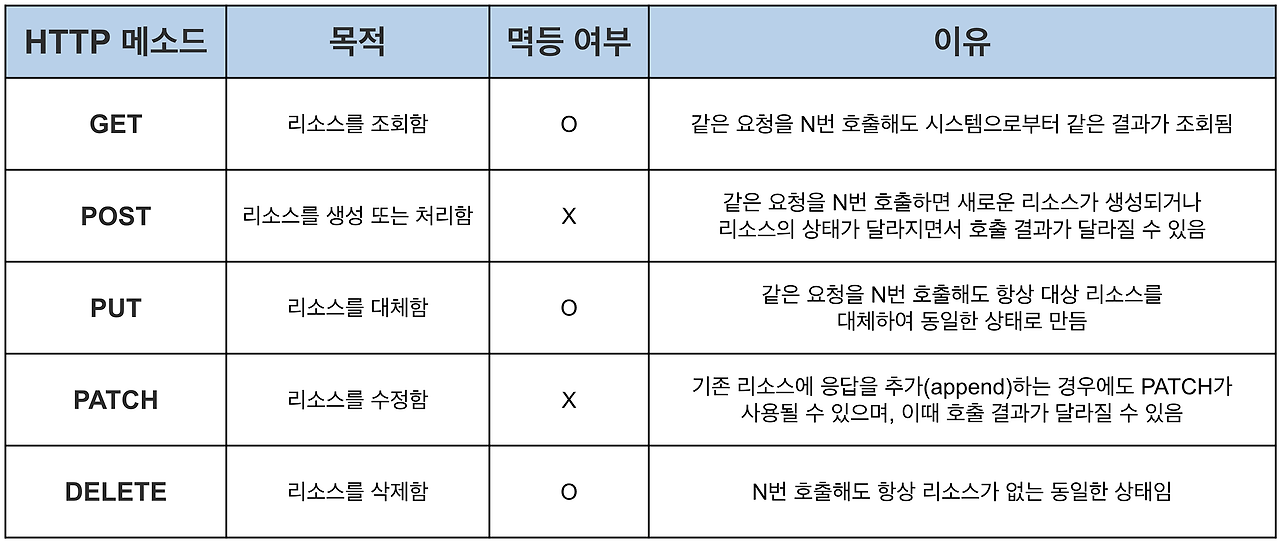
❓PUT은 멱등성 메서드이고 PATCH는 비멱등성 메서드인 이유
PUT요청은 데이터를 덮어쓰기 하는 것으로 요청 시 수정할 데이터 일부분만 보낸다면 일부분에 해당하지 않는 값은 NULL값을 가지게 된다. 하지만 이 요청 역시 처음 요청에 대한 서버상태와 여러번 요청에 대한 서버 상태가 같으므로 멱등성을 가진다.
기존 데이터
{
name : 'abc',
age : 20
}
PUT
{
name : 'kdk'
}
응답
{
name : 'kdk',
age : NULL
}
PATCH는 기본적으로 멱등성을 가지지 않지만, PUT과 동일한 방식으로 쓴다면 멱등성을 가질 수 있다. 하지만 추가하는 요청 역시 PATCH를 쓸 수 있어 결과가 매번 달라지는 추가 요청은 멱등성을 가진다고 할 수 없다.
1. PATCH → name: [”MangKyu”]
2. PATCH → name: [”MangKyu”, ”MangKyu”]
3. PATCH → name: [”MangKyu”, ”MangKyu”, ”MangKyu”]
멱등성은 클라이언트가 받는 응답 상태 코드가 달라질 수 있음에도 불구하고 유지될 수 있다. 멱등성의 기준이 상태 코드가 아니기 때문이다. 예를 들어 DELETE를 여러번 호출하면 200 OK에서 404 NOT FOUND로 상태 코드가 변할 것이다. 그러나 DELETE의 목적은 리소스를 삭제하여 서버에 리소스가 없도록 만드는 것이고 DELETE를 여러 번 호출해도 응답 상태와 무관하게 리소스가 없는 상태를 유지한다. 따라서 멱등한 것이다.
결국 멱등성은 리소스 관점에서 생각하는 것이 중요하다. 여러 번 요청해도 같은 효과를 지니고 서버의 상태도 동일하다면 멱등한 것으로 봐도 된다.